AI
Copilot系列
- Copilot系列
Github Copilot付费模型对比
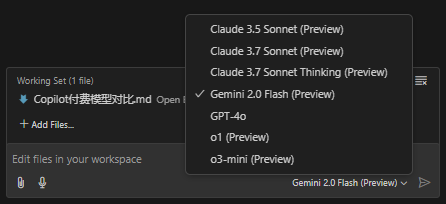
Github Copilot 目前提供了 7 种模型,
- Claude 3.5 Sonnet
- Claude 3.7 Sonnet
- Claude 3.7 Sonnet Thinking
- Gemini 2.0 Flash
- GPT-4o
- o1
- o3-mini
官方缺少对这 7 种模型的介绍, 本文简略的描述它们在各领域的评分, 以区分它们擅长的领域, 方便读者在处理特定问题时, 切换到更合适的模型.
模型对比
基于公开评测数据(部分数据为估算与不同来源折算后得出)的多维度对比表,涵盖编码(SWE‑Bench Verified)、数学(AIME’24)和推理(GPQA Diamond)三个关键指标:
| 模型 | 编码表现 (SWE‑Bench Verified) |
数学表现 (AIME'24) |
推理表现 (GPQA Diamond) |
|---|---|---|---|
| Claude 3.5 Sonnet | 70.3% | 49.0% | 77.0% |
| Claude 3.7 Sonnet (标准模式) | ≈83.7% (提高 ≈19%) |
≈58.3% (提高 ≈19%) |
≈91.6% (提高 ≈19%) |
| Claude 3.7 Sonnet Thinking | ≈83.7% (与标准相近) |
≈64.0% (思考模式进一步提升) |
≈95.0% (更强推理能力) |
| Gemini 2.0 Flash | ≈65.0% (估算) |
≈45.0% (估算) |
≈75.0% (估算) |
| GPT‑4o | 38.0% | 36.7% | 71.4% |
| o1 | 48.9% | 83.3% | 78.0% |
| o3‑mini | 49.3% | 87.3% | 79.7% |
说明:
- 上表数值取自部分公开评测(例如 Vellum 平台的对比报告 VELLUM.AI)以及部分数据折算(例如 Claude 3.7 相比 3.5 大约提升 19%),部分 Gemini 2.0 Flash 数值为估算值。
- “Claude 3.7 Sonnet Thinking”指的是在开启“思考模式”(即延长内部推理步骤)的情况下,模型在数学与推理任务上的表现显著改善。
优劣势总结与应用领域
Claude 系列(3.5/3.7 Sonnet 与其 Thinking 变体)
- 优势: 在编码和多步推理任务上具有较高准确率,尤其是 3.7 版本较 3.5 有明显提升; “Thinking”模式下数学和推理表现更佳,适合处理复杂逻辑或需要详细计划的任务; 内置对工具调用和长上下文处理有优势。
- 劣势: 标准模式下数学指标相对较低,只有在开启延长推理时才能显著改善; 成本和响应时长在某些场景下可能较高。 适用领域: 软件工程、代码生成与调试、复杂问题求解、多步决策及企业级自动化工作流。
Gemini 2.0 Flash
- 优势: 具备较大上下文窗口,适合长文档处理与多模态输入(例如图像解析); 推理能力与编码表现在部分测试中表现不俗,且响应速度快。
- 劣势: 部分场景下(如复杂编码任务)可能会出现“卡住”现象,稳定性有待验证; 部分指标为初步估算,整体表现仍需更多公开数据确认。 适用领域: 多模态任务、实时交互、需要大上下文的应用场景,如长文档摘要、视频解析及信息检索。
GPT‑4o
- 优势: 语言理解和生成自然流畅,适合开放性对话和一般文本处理。
- 劣势: 在编码、数学等专业任务上的表现相对较弱,部分指标远低于同类模型; 成本较高(与 GPT‑4.5 类似),性价比不如部分竞争对手。 适用领域: 通用对话系统、内容创作、文案撰写及日常问答任务。
o1 与 o3‑mini(OpenAI 系列)
- 优势: 数学推理方面表现出色,o1 与 o3‑mini 在 AIME 类任务上分别达到 83.3% 和 87.3%; 推理能力较稳定,适合需要高精度数学和逻辑分析的应用。
- 劣势: 编码表现中等,相较于 Claude 系列稍逊一筹; 整体性能在不同任务上表现略有不平衡。 适用领域: 科学计算、数学问题求解、逻辑推理、教育辅导及专业数据分析领域。
Github Copilot Agent模式使用经验分享
本文总结了如何使用 GitHub Copilot Agent 模式,并分享实际操作经验。
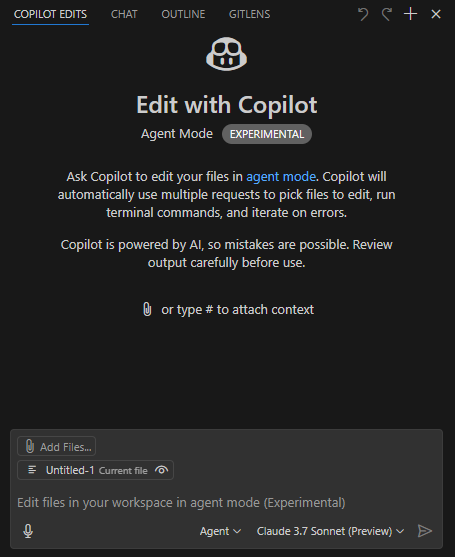
前置设置
- 使用 VSCode Insider;
- 安装 GitHub Copilot(预览版)插件;
- 选择 Claude 3.7 Sonnet(预览版)模型,该模型在代码编写方面表现出色,同时其它模型在速度、多模态(如图像识别)及推理能力上具备优势;
- 工作模式选择 Agent。
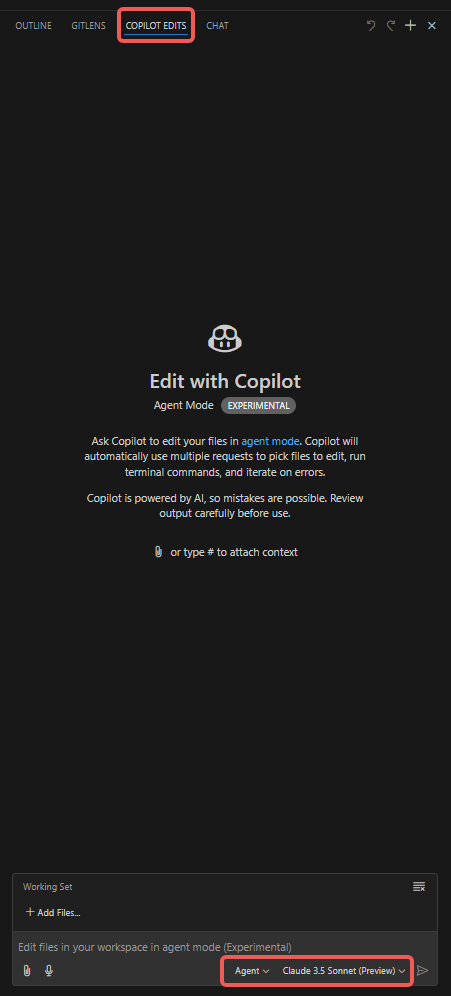
操作步骤
- 打开 “Copilot Edits” 选项卡;
- 添加附件,如 “Codebase”、“Get Errors”、“Terminal Last Commands” 等;
- 添加 “Working Set” 文件,默认包含当前打开的文件,也可手动选择其他文件(如 “Open Editors”);
- 添加 “Instructions”,输入需要 Copilot Agent 特别注意的提示词;
- 点击 “Send” 按钮,开始对话,观察 Agent 的表现。
其它说明
- VSCode 通过语言插件提供的 lint 功能可以产生 Error 或 Warning 提示,Agent 能自动根据这些提示修正代码。
- 随着对话的深入,Agent 生成的代码修改可能会偏离预期。建议每次会话都聚焦一个明确的主题,避免对话过长;达到短期目标后结束当前会话,再启动新任务。
- “Working Set” 下的 “Add Files” 提供 “Related Files” 选项,可推荐相关文件。
- 注意控制单个代码文件的行数,以免 token 消耗过快。
- 建议先生成基础代码,再编写测试用例,便于 Agent 根据测试结果调试和自我校验。
- 为限制修改范围,可在 settings.json 中添加如下配置,只修改指定目录下的文件, 仅供参考:
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "只需修改 ./script/ 目录下的文件,不修改其他目录下的文件."
},
{
"text": "若目标代码文件行数超过 1000 行,建议将新增函数置于新文件中,通过引用调用;如产生的修改导致文件超长,可暂不严格遵守此规则."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "在现有单元测试文件中生成测试用例."
},
{
"text": "代码修改后务必运行测试用例验证."
}
],
常见问题
输入需求得不到想要的业务代码
需要将大任务拆分成较小的任务, 每次会话只处理一个小任务. 这是由于大模型的上下文太多会导致注意力分散.
喂给单次对话的上下文, 需要自己揣摩, 太多和太少都会导致不理解需求.
DeepSeek 模型解决了注意力分散问题, 但需要在 cursor 中使用 Deepseek API. 不清楚其效果如何.
响应缓慢问题
需要理解 token 消耗机制, token 输入是便宜且耗时较短的, token 输出贵很多, 且明显更缓慢.
假如一个代码文件非常大, 实际需要修改的代码行只有三行, 但由于上下文多, 输出也多, 会导致 token 消耗很快, 且响应缓慢.
因此, 必须要考虑控制文件的大小, 不要写很大的文件和很大的函数. 及时拆分大文件, 大函数, 通过引用调用.
业务理解问题
理解问题或许有些依赖代码中的注释, 以及测试文件, 代码中补充足够的注释, 以及测试用例, 有助于 Copilot Agent 更好的理解业务.
Agent 自己生成的业务代码就有足够多的注释, 检视这些注释, 就可以快速判断 Agent 是否正确理解了需求.
生成大量代码需要 debug 较久
可以考虑在生成某个特性的基础代码后, 先生成测试用例, 再调整业务逻辑,这样 Agent 可以自行进行调试,自我验证.
Agent 会询问是否允许运行测试命令, 运行完成后会自行读终端输出, 以此来判断代码是否正确. 如果不正确, 会根据报错信息进行修改. 循环往复, 直到测试通过.
也就是需要自己更多理解业务, 需要手动写的时候并不太多, 如果测试用例代码和业务代码都不正确, Agent 既不能根据业务写出正确用例, 也不能根据用例写出正确业务代码, 这种情况才会出现 debug 较久的情况.
总结
理解大模型的 token 消耗机制, 输入的上下文很便宜,输出的代码较贵,文件中未修改的代码部分可能也算作输出, 证据是很多无需修改的代码也会缓慢输出.
因此应尽量控制单文件的大小, 可以在使用中感受 Agent 在处理大文件和小文件时, 响应速度上的差异, 这个差异是非常明显的.
Copilot使用入门
GitHub Copilot 是一款基于机器学习的代码补全工具,能帮助你更快速地编写代码并提升编码效率。
Copilot Labs 能力
| 能力 | 说明 | 备注 | example |
|---|---|---|---|
Explain |
生成代码片段的解释说明 | 有高级选项定制提示词, 更清晰说明自己的需求 | 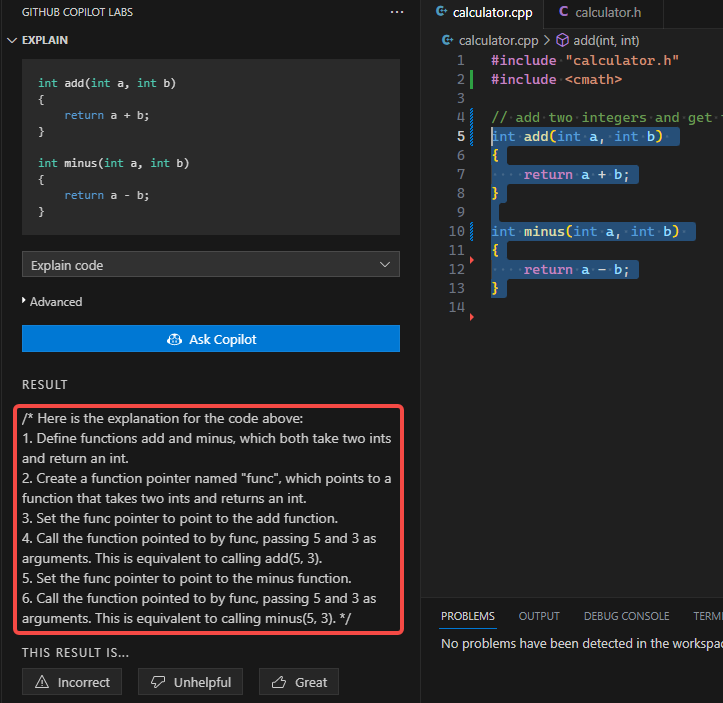 |
Show example code |
生成代码片段的示例代码 | 有高级选项定制 | 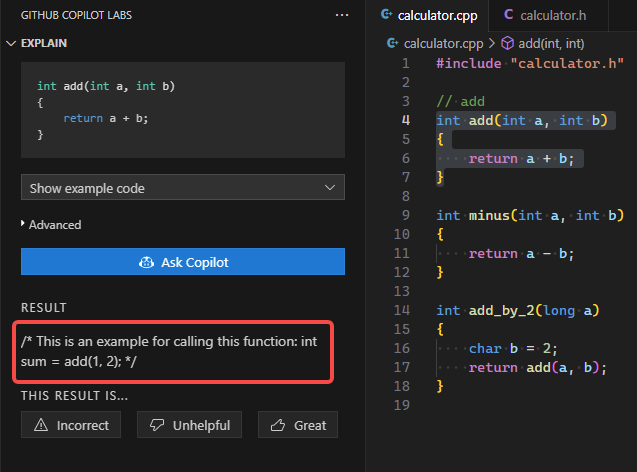 |
Language Translation |
生成代码片段的翻译 | 此翻译是基于编程语言的翻译, 比如C++ -> Python | 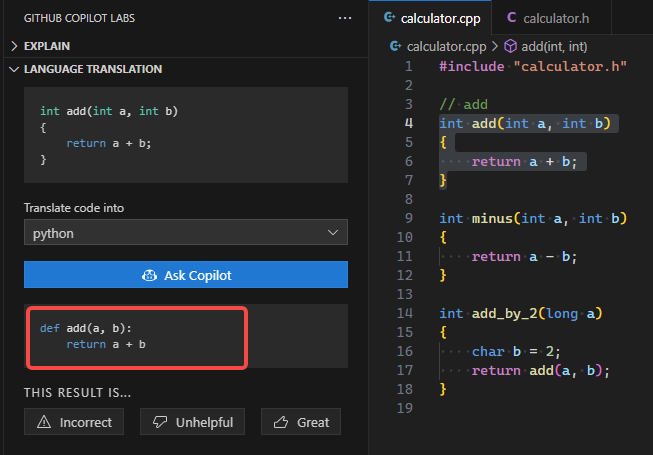 |
Readable |
提高一段代码的可读性 | 不是简单的格式化, 是真正的可读性提升 | 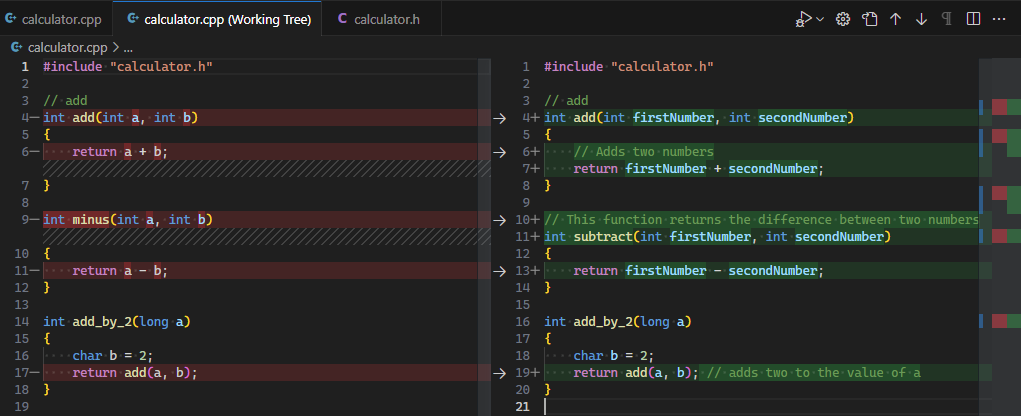 |
Add Types |
类型推测 | 将自动类型的变量改为明确的类型 | 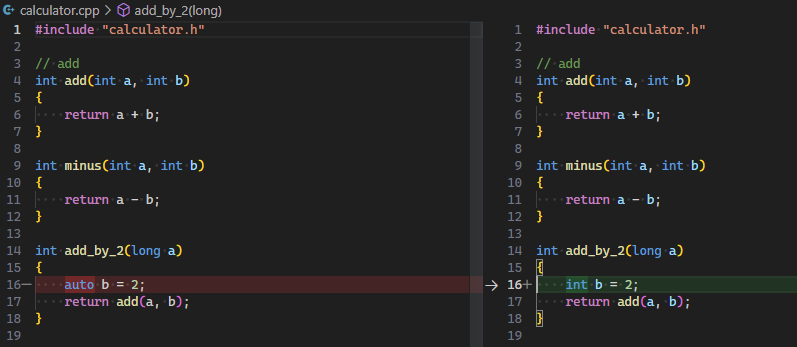 |
Fix bug |
修复 bug | 修复一些常见的 bug |  |
Debug |
使代码更容易调试 | 增加打印日志, 或增加临时变量以用于断点 | 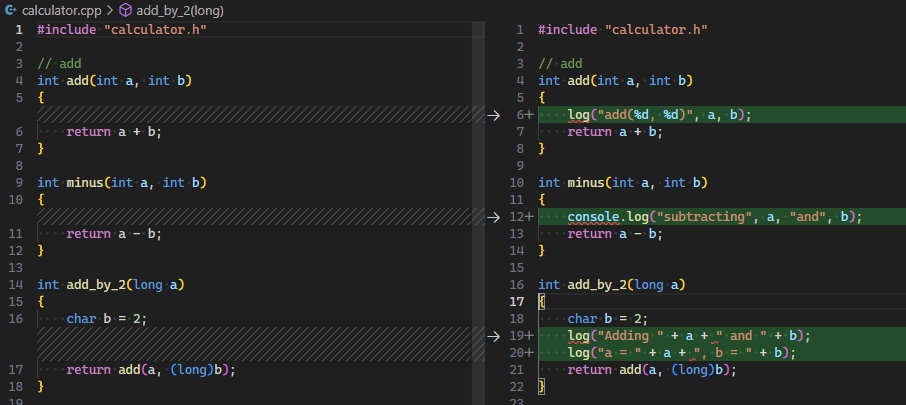 |
Clean |
清理代码 | 清理代码的无用部分, 注释/打印/废弃代码等 | 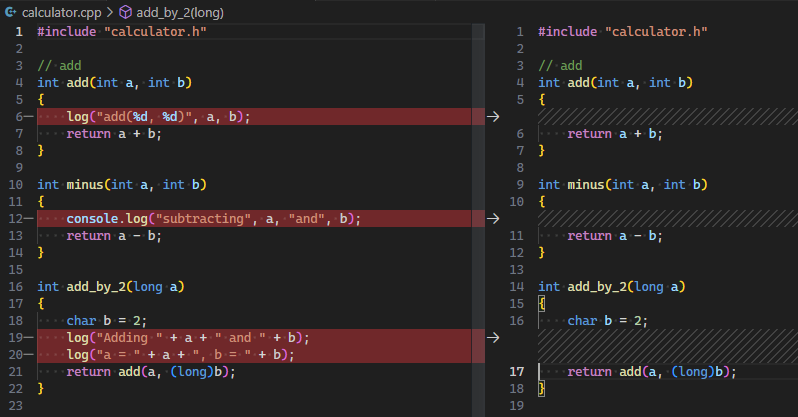 |
List steps |
列出代码的步骤 | 有的代码的执行严格依赖顺序, 需要明确注释其执行顺序 | 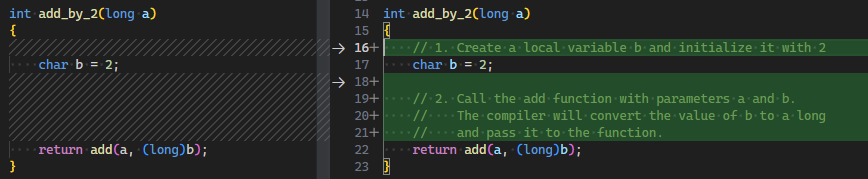 |
Make robust |
使代码更健壮 | 考虑边界/多线程/重入等 | 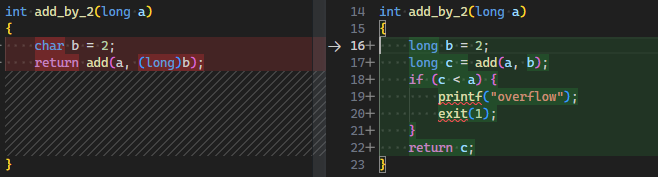 |
Chunk |
将代码分块 | 一般希望函数有效行数<=50, 嵌套<=4, 扇出<=7, 圈复杂度<=20 | 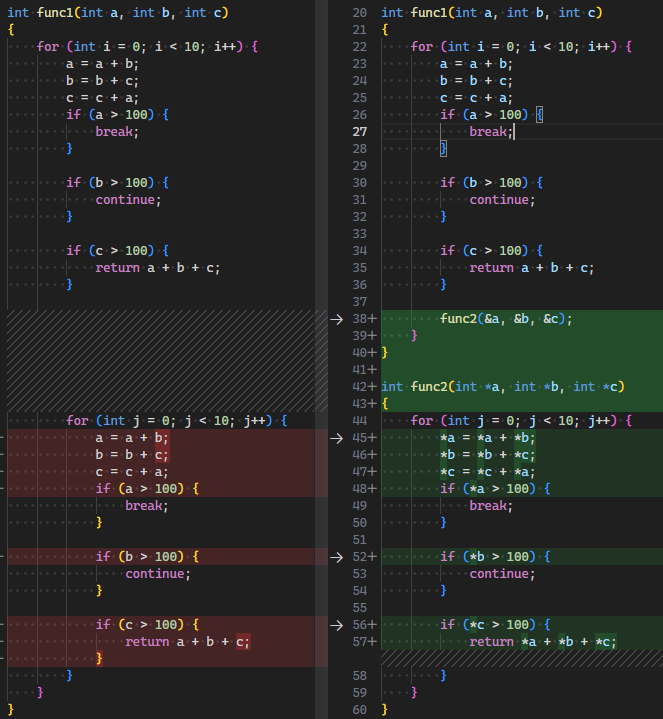 |
Document |
生成代码的文档 | 通过写注释生成代码, 还可以通过代码生成注释和文档 |  |
Custom |
自定义操作 | 告诉 copilot 如何操作你的代码 | 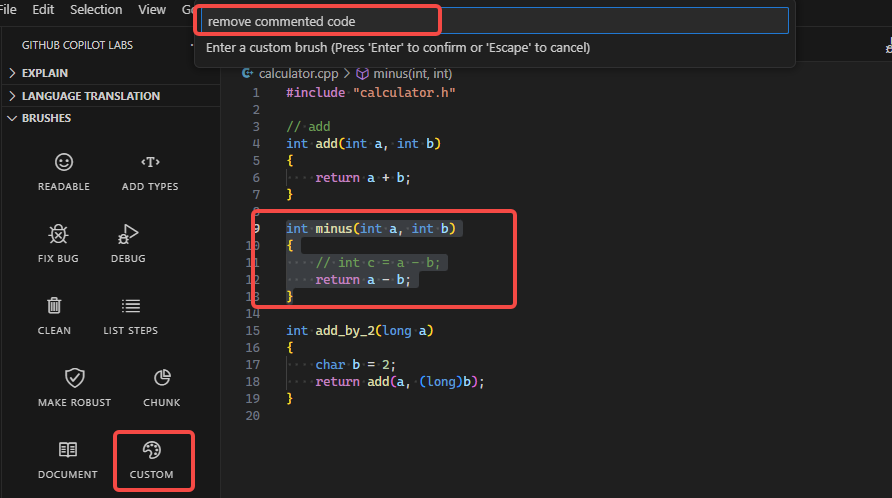 |
Copilot 是什么
官网 的介绍简单明了:Your AI pair programmer —— 你的结对程序员
结对编程:是一种敏捷软件开发方法,两个程序员在同一台计算机前协作:一人键入代码,另一人审视每行代码。角色时常互换,确保逻辑严谨、问题预防。
Copilot 通过以下方式参与编码工作, 实现扮演结对程序员这一角色.
理解
Copilot 是个大语言模型, 它不能理解我们的代码, 我们也不能理解 Copilot 的模型, 这里的理解是一名程序员与一群程序员之间的相互理解. 大家基于一些共识而一起写代码.
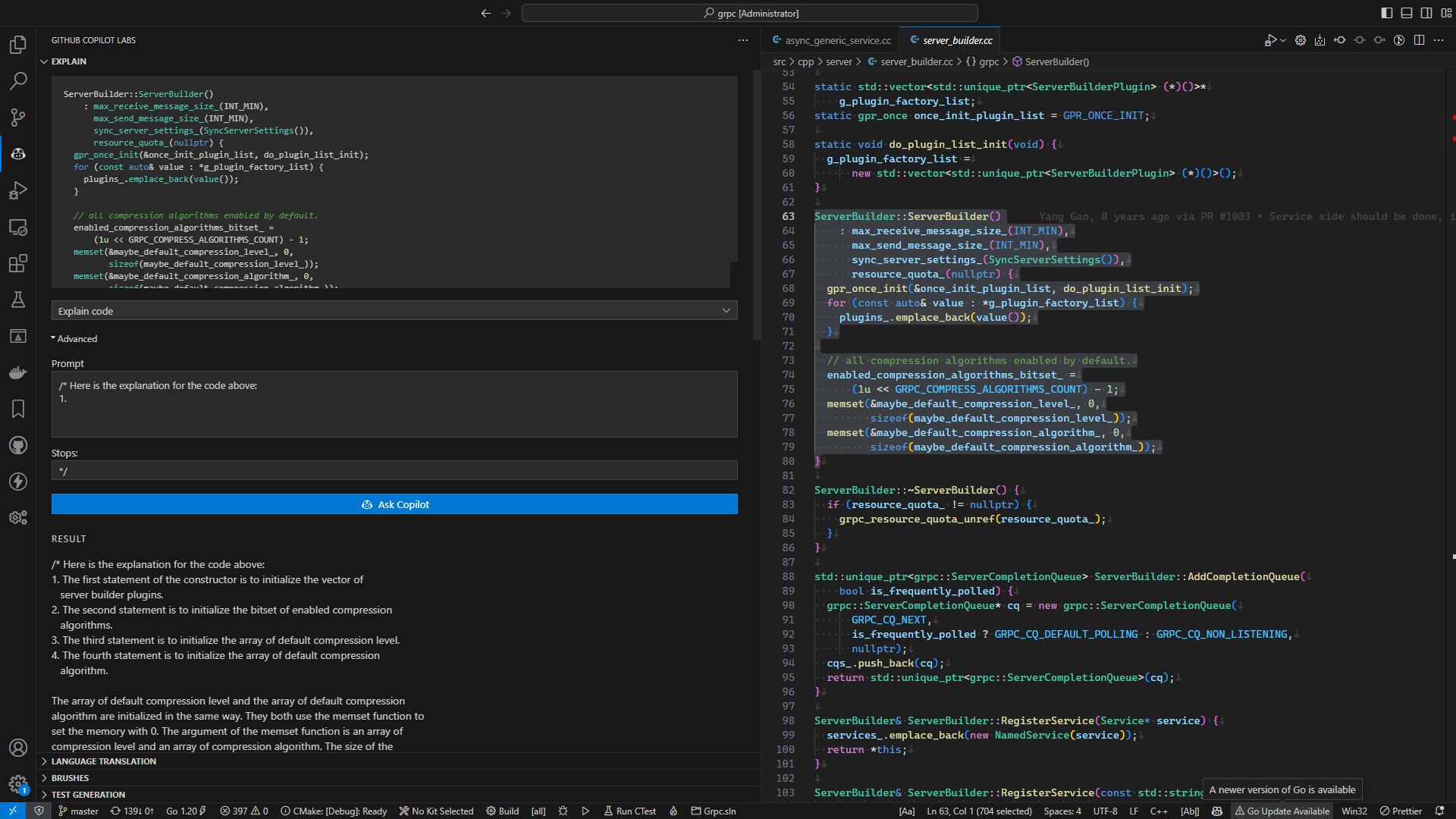
Copilot 搜集信息以理解上下文, 信息包括:
- 正在编辑的代码
- 关联文件
- IDE 已打开文件
- 库地址
- 文件路径
Copilot 不仅仅是通过一行注释去理解, 它搜集了足够多的上下文信息来理解下一步将要做什么.
建议
| 整段建议 | inline 建议 |
|---|---|
 |
 |
众所周知,最常见的获取建议方式是通过描述需求的注释而非直接编写代码,从而引导 GitHub Copilot 给出整段建议. 但这可能会造成注释冗余的问题, 注释不是越多越好, 注释可以帮助理解, 但它不是代码主体. 良好的代码没有注释也清晰明了, 依靠的是合适的命名, 合理的设计以及清晰的逻辑. 使用 inline 建议时, 只要给出合适的变量名/函数名/类名, Copilot 总能给出合适的建议.
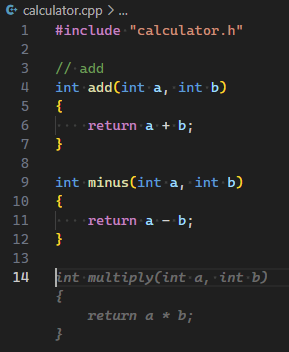
除了合适的外部输入外, Copilot 也支持支持根据已有的代码片段给出建议, Copilot Labs->Show example code可以帮助生成指定函数的示例代码, 只需要选中代码, 点击Show example code.
Ctrl+Enter, 总是能给人非常多的启发, 我创建了三个文件, 一个 main.cpp 空文件, 一个 calculator.h 空文件, 在 calculator.cpp 中实现"加"和"减", Copilot 给出了如下建议内容:
- 添加"乘"和"除"的实现
- 在 main 中调用"加减乘除"的实现
- calculator 静态库的创建和使用方法
- main 函数的运行结果, 并且结果正确
- calculator.h 头文件的建议内容
- g++编译命令
- gtest 用例
- CMakeLists.txt 的内容, 并包含测试
- objdump -d main > main.s 查看汇编代码, 并显示了汇编代码
- ar 查看静态库的内容, 并显示了静态库的内容
默认配置下, 每次敲击Ctrl+Enter展示的内容差异很大, 无法回看上次生成的内容, 如果需要更稳定的生成内容, 可以设置temperature的值[0, 1]. 值越小, 生成的内容越稳定; 值越大, 生成的内容越难以捉摸.
以上建议内容远超了日常使用的一般建议内容, 可能是由于工程确实过于简单, 一旦把编译文件, 头文件写全, 建议就不会有这么多了, 但它仍然常常具有很好的启发作用.
使用 Copilot 建议的快捷键
| Action | Shortcut | Command name |
|---|---|---|
| 接受 inline 建议 | Tab |
editor.action.inlineSuggest.commit |
| 忽略建议 | Esc |
editor.action.inlineSuggest.hide |
| 显示下一条 inline 建议 | Alt+] |
editor.action.inlineSuggest.showNext |
| 显示上一条 inline 建议 | Alt+[ |
editor.action.inlineSuggest.showPrevious |
| 触发 inline 建议 | Alt+\ |
editor.action.inlineSuggest.trigger |
| 在单独面板显示更多建议 | Ctrl+Enter |
github.copilot.generate |
调试
一般两种调试方式, 打印和断点.
- Copilot 可以帮助自动生成打印代码, 根据上下文选用格式的打印或日志.
- Copilot 可以帮助修改已有代码结构, 提供方便的断点位置. 一些嵌套风格的代码难以打断点, Copilot 可以直接修改它们.
Copilot Labs 预置了以下功能:
- Debug, 生成调试代码, 例如打印, 断点, 以及其他调试代码.
检视
检视是相互的, 我们和 copilot 需要经常相互检视, 不要轻信快速生成的代码.
Copilot Labs 预置了以下功能:
- Fix bug, 直接修复它发现的 bug, 需要先保存好自己的代码, 仔细检视 Copilot 的修改.
- Make robust, 使代码更健壮, Copilot 会发现未处理的情况, 生成改进代码, 我们应该受其启发, 想的更缜密一些.
重构
Copilot Labs 预置了以下功能:
- Readable, 提高可读性, 真正的提高可读性, 而不是简单的格式化, 但是要务必小心的检视 Copilot 的修改.
- Clean, 使代码更简洁, 去除多余的代码.
- Chunk, 使代码更易于理解, 将代码分块, 将一个大函数分成多个小函数.
文档
Copilot Labs 预置了以下功能:
- Document, 生成文档, 例如函数注释, 以及其他文档.
使用 Custom 扩展 Copilot 边界
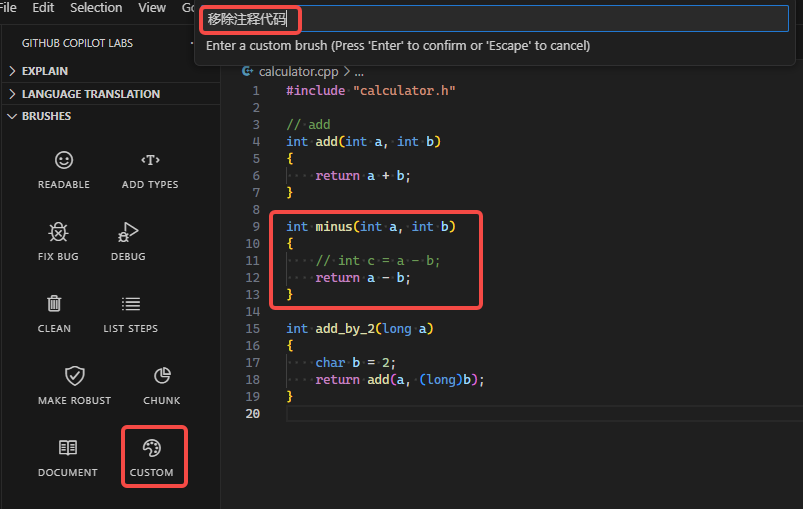
Custom不太起眼, 但它让 Copilot 具有无限可能. 我们可以将它理解为一种新的编程语言, 这种编程语言就是英语或者中文.
你可以通过 Custom 输入
-
移除注释代码
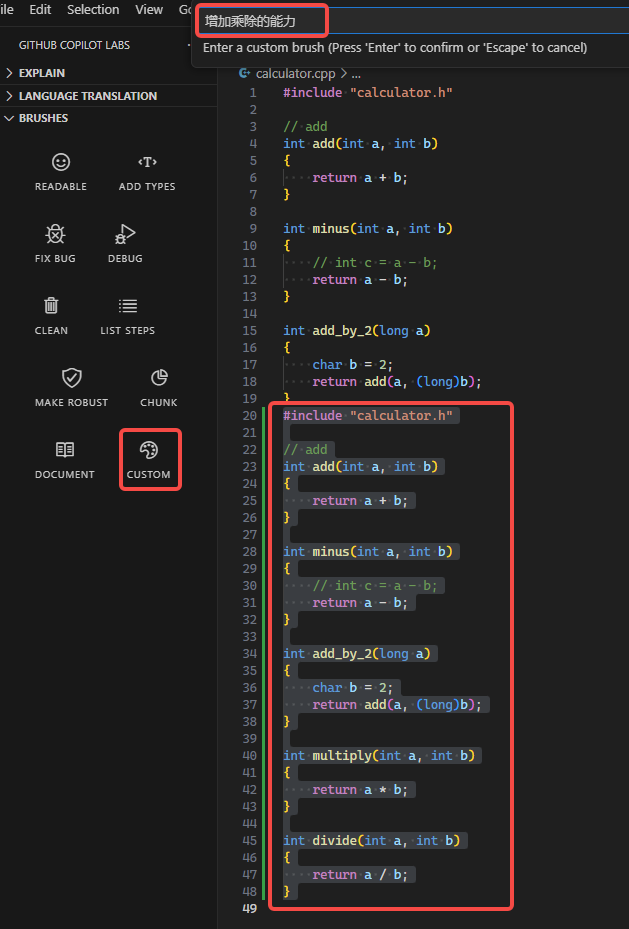
-
增加乘除的能力
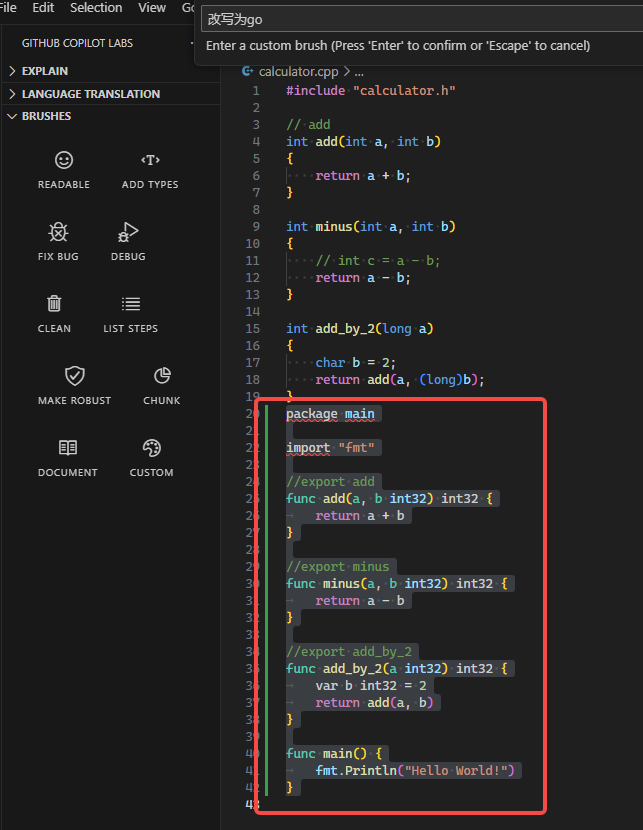
-
改写为go
-
添加三角函数计算
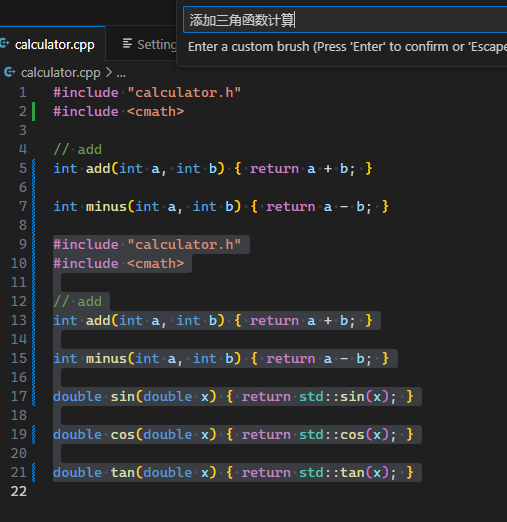
-
添加微分计算, 中文这里不好用了, 使用support calculate differential, 在低温模式时, 没有靠谱答案, 高温模式时, 有几个离谱答案.
在日常工作中, 随时可以向 Copilot 提出自己的需求, 通过 Custom 能力, 可以让 Copilot 帮助完成许多想要的操作.
一些例子:
| prompts | 说明 |
|---|---|
generate the cmake file |
生成 cmake 文件 |
generate 10 test cases for tan() |
生成 10 个测试用例 |
format like google style |
格式化代码 |
考虑边界情况 |
考虑边界情况 |
确认释放内存 |
确认释放内存 |
Custom 用法充满想象力, 但有时也不那么靠谱, 建议使用前保存好代码, 然后好好检视它所作的修改.
获得更专业的建议
给 Copilot 的提示越清晰, 它给的建议越准确, 专业的提示可以获得更专业的建议. 许多不合适的代码既不影响代码编译, 也不影响业务运行, 但影响可读性, 可维护性, 扩展性, 复用, 这些特性也非常重要, 如果希望获得更专业的建议, 我们最好了解一些最佳实践的英文名称.
- 首先是使用可被理解的英文, 可以通过看开源项目学习英语.
- 命名约定, 命名是概念最基础的定义, 好的命名可以避免产生歧义, 避免阅读者陷入业务细节, 从而提高代码的可读性, 也是一种最佳实践.
- 通常只需要一个合理的变量名, Copilot 就能给出整段的靠谱建议.
- 设计模式列表, 设计模式是一种解决问题的模板, 针对不同问题合理取舍SOLID设计基本原则, 节省方案设计时间, 提高代码的质量.
- 只需要写出所需要的模式名称, Copilot 就能生成完整代码片段.
- 算法列表, 好的算法是用来解决一类问题的高度智慧结晶, 开发者需自行将具体问题抽象, 将数据抽象后输入到算法.
- 算法代码通常是通用的, 只需要写出算法名称, Copilot 就能生成算法代码片段, 并且 Copilot 总是能巧妙的将上下文的数据结构合理运用到算法中.
纯文本的建议
| en | zh |
|---|---|
| GitHub Copilot uses the OpenAI Codex to suggest code and entire functions in real-time, right from your editor. | GitHub Copilot 使用 OpenAI Codex 在编辑器中实时提供代码和整个函数的建议。 |
| Trained on billions of lines of code, GitHub Copilot turns natural language prompts into coding suggestions across dozens of languages. | 通过数十亿行代码的训练,GitHub Copilot 将自然语言提示转换为跨语言的编码建议。 |
| Don’t fly solo. Developers all over the world use GitHub Copilot to code faster, focus on business logic over boilerplate, and do what matters most: building great software. | 不要孤军奋战。世界各地的开发人员都在使用 GitHub Copilot 来更快地编码,专注于业务逻辑而不是样板代码,并且做最重要的事情:构建出色的软件。 |
| Focus on solving bigger problems. Spend less time creating boilerplate and repetitive code patterns, and more time on what matters: building great software. Write a comment describing the logic you want and GitHub Copilot will immediately suggest code to implement the solution. | 专注于解决更大的问题。花更少的时间创建样板和重复的代码模式,更多的时间在重要的事情上:构建出色的软件。编写描述您想要的逻辑的注释,GitHub Copilot 将立即提供代码以实现该解决方案。 |
| Get AI-based suggestions, just for you. GitHub Copilot shares recommendations based on the project’s context and style conventions. Quickly cycle through lines of code, complete function suggestions, and decide which to accept, reject, or edit. | 获得基于 AI 的建议,只为您。GitHub Copilot 根据项目的上下文和风格约定共享建议。快速循环代码行,完成函数建议,并决定接受,拒绝或编辑哪个。 |
| Code confidently in unfamiliar territory. Whether you’re working in a new language or framework, or just learning to code, GitHub Copilot can help you find your way. Tackle a bug, or learn how to use a new framework without spending most of your time spelunking through the docs or searching the web. | 在不熟悉的领域自信地编码。无论您是在新的语言或框架中工作,还是刚刚开始学习编码,GitHub Copilot 都可以帮助您找到自己的方式。解决 bug,或者在不花费大部分时间在文档或搜索引擎中寻找的情况下学习如何使用新框架。 |
这些翻译都由 Copilot 生成, 不能确定这些建议是基于模型生成, 还是基于翻译行为产生. 事实上你在表的en列中写的任何英语内容, 都可以被 Copilot 翻译(生成)到zh列中的内容.

设置项
客户端设置项
| 设置项 | 说明 | 备注 |
|---|---|---|
| temperature | 采样温度 | 0.0 - 1.0, 0.0 生成最常见的代码片段, 1.0 生成最不常见更随机的代码片段 |
| length | 生成代码建议的最大长度 | 默认 500 |
| inlineSuggestCount | 生成行内建议的数量 | 默认 3 |
| listCount | 生成建议的数量 | 默认 10 |
| top_p | 优先展示概率前 N 的建议 | 默认展示全部可能的建议 |
个人账户设置有两项设置, 一个是版权相关, 一个是隐私相关.
- 是否使用开源代码提供建议, 主要用于规避 Copilot 生成的代码片段中的版权问题, 避免开源协议限制.
- 是否允许使用个人的代码片段改进产品, 避免隐私泄露风险.
数据安全
Copilot 的信息收集
- 商用版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后立刻丢弃, 不保留任何代码片段
- 数据共享, GitHub, Microsoft, OpenAI
- 个人版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后, 根据个人 telemetry 设置, 保留或丢弃
- 代码片段包含, 正在编辑的代码, 关联文件, IDE 已打开文件, 库地址, 文件路径
- 数据共享, GitHub, Microsoft, OpenAI
- 代码数据保护, 1. 加密. 2. Copilot 团队相关的 Github/OpenAI 的部分员工可看. 3. 访问时需基于角色的访问控制和多因素验证
- 避免代码片段被使用(保留或训练), 1. 设置 2. 联系 Copilot 团队
- 私有代码是否会被使用? 不会.
- 是否会输出个人信息(姓名生日等)? 少见, 还在改进.
- 详细隐私声明
常见问题
- Copilot 的训练数据, 来自 Github 的公开库.
- Copilot 写的代码完美吗? 不一定.
- 可以为新平台写代码吗? 暂时能力有限.
- 如何更好的使用 Copilot? 拆分代码为小函数, 用自然语言描述函数的功能, 以及输入输出, 使用有具体意义的变量名和函数名.
- Copilot 生成的代码会有 bug 吗? 当然无法避免.
- Copilot 生成的代码可以直接使用吗? 不一定, 有时候需要修改.
- Copilot 生成的代码可以用于商业项目吗? 可以.
- Copilot 生成的代码属于 Copilot 的知识产权吗? 不属于.
- Copilot 是从训练集里拷贝的代码吗? Copilot 不拷贝代码, 极低概率会出现超过 150 行代码能匹配到训练集, 以下两种情况会出现
- 在上下文信息非常少时
- 是通用问题的解决方案
- 如何避免与公开代码重复, 设置filter
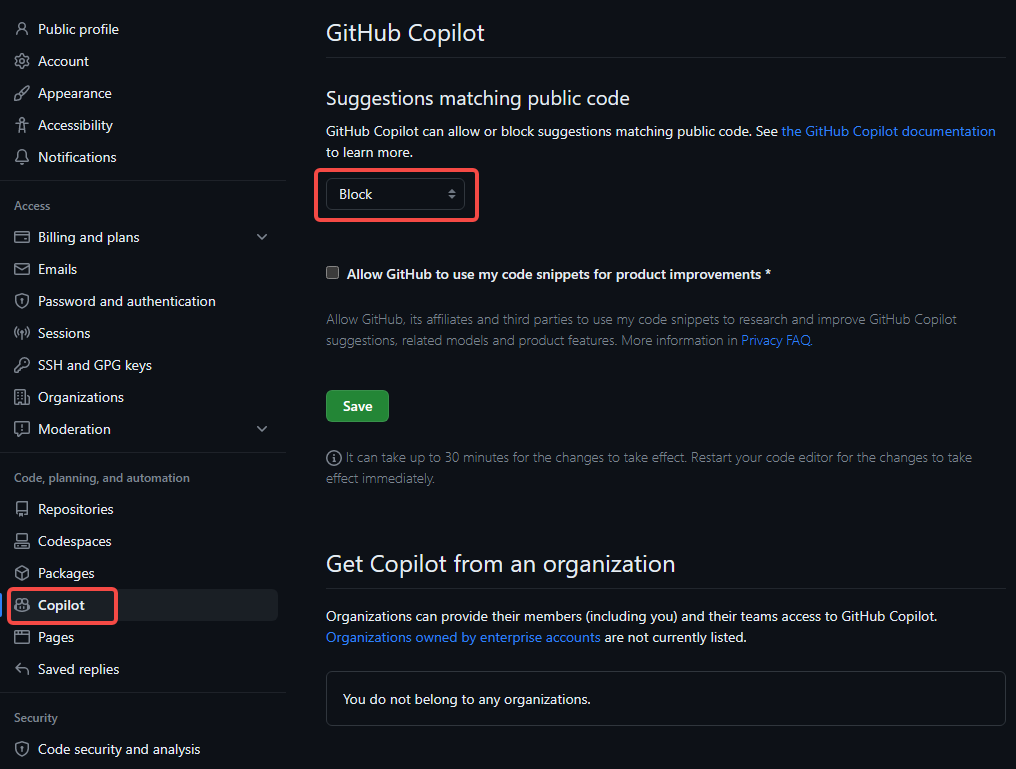
- 如何正确的使用 Copilot 生成的代码? 1. 自行测试/检视生成代码; 2. 不要在检视前自动编译或运行生成的代码.
- Copilot 是否在每种自然语言都有相同的表现? 最佳表现是英语.
- Copilot 是否会生成冒犯性内容? 已有过滤, 但是不排除可能出现.
Copilot使用入门
- 文档已过期
GitHub Copilot 是一款基于机器学习的代码补全工具,能帮助你更快速地编写代码并提升编码效率。
Copilot Labs 能力
| 能力 | 说明 | 备注 | example |
|---|---|---|---|
Explain |
生成代码片段的解释说明 | 有高级选项定制提示词, 更清晰说明自己的需求 | |
Show example code |
生成代码片段的示例代码 | 有高级选项定制 | |
Language Translation |
生成代码片段的翻译 | 此翻译是基于编程语言的翻译, 比如C++ -> Python | |
Readable |
提高一段代码的可读性 | 不是简单的格式化, 是真正的可读性提升 | |
Add Types |
类型推测 | 将自动类型的变量改为明确的类型 | |
Fix bug |
修复 bug | 修复一些常见的 bug | |
Debug |
使代码更容易调试 | 增加打印日志, 或增加临时变量以用于断点 | |
Clean |
清理代码 | 清理代码的无用部分, 注释/打印/废弃代码等 | |
List steps |
列出代码的步骤 | 有的代码的执行严格依赖顺序, 需要明确注释其执行顺序 | |
Make robust |
使代码更健壮 | 考虑边界/多线程/重入等 | |
Chunk |
将代码分块 | 一般希望函数有效行数<=50, 嵌套<=4, 扇出<=7, 圈复杂度<=20 | |
Document |
生成代码的文档 | 通过写注释生成代码, 还可以通过代码生成注释和文档 | |
Custom |
自定义操作 | 告诉 copilot 如何操作你的代码 | |
Copilot 是什么
官网 的介绍简单明了:Your AI pair programmer —— 你的结对程序员
结对编程:是一种敏捷软件开发方法,两个程序员在同一台计算机前协作:一人键入代码,另一人审视每行代码。角色时常互换,确保逻辑严谨、问题预防。
Copilot 通过以下方式参与编码工作, 实现扮演结对程序员这一角色.
理解
Copilot 是个大语言模型, 它不能理解我们的代码, 我们也不能理解 Copilot 的模型, 这里的理解是一名程序员与一群程序员之间的相互理解. 大家基于一些共识而一起写代码.
Copilot 搜集信息以理解上下文, 信息包括:
- 正在编辑的代码
- 关联文件
- IDE 已打开文件
- 库地址
- 文件路径
Copilot 不仅仅是通过一行注释去理解, 它搜集了足够多的上下文信息来理解下一步将要做什么.
建议
| 整段建议 | inline 建议 |
|---|---|
|
|
众所周知,最常见的获取建议方式是通过描述需求的注释而非直接编写代码,从而引导 GitHub Copilot 给出整段建议. 但这可能会造成注释冗余的问题, 注释不是越多越好, 注释可以帮助理解, 但它不是代码主体. 良好的代码没有注释也清晰明了, 依靠的是合适的命名, 合理的设计以及清晰的逻辑. 使用 inline 建议时, 只要给出合适的变量名/函数名/类名, Copilot 总能给出合适的建议.
除了合适的外部输入外, Copilot 也支持支持根据已有的代码片段给出建议, Copilot Labs->Show example code可以帮助生成指定函数的示例代码, 只需要选中代码, 点击Show example code.
Ctrl+Enter, 总是能给人非常多的启发, 我创建了三个文件, 一个 main.cpp 空文件, 一个 calculator.h 空文件, 在 calculator.cpp 中实现"加"和"减", Copilot 给出了如下建议内容:
- 添加"乘"和"除"的实现
- 在 main 中调用"加减乘除"的实现
- calculator 静态库的创建和使用方法
- main 函数的运行结果, 并且结果正确
- calculator.h 头文件的建议内容
- g++编译命令
- gtest 用例
- CMakeLists.txt 的内容, 并包含测试
- objdump -d main > main.s 查看汇编代码, 并显示了汇编代码
- ar 查看静态库的内容, 并显示了静态库的内容
默认配置下, 每次敲击Ctrl+Enter展示的内容差异很大, 无法回看上次生成的内容, 如果需要更稳定的生成内容, 可以设置temperature的值[0, 1]. 值越小, 生成的内容越稳定; 值越大, 生成的内容越难以捉摸.
以上建议内容远超了日常使用的一般建议内容, 可能是由于工程确实过于简单, 一旦把编译文件, 头文件写全, 建议就不会有这么多了, 但它仍然常常具有很好的启发作用.
使用 Copilot 建议的快捷键
| Action | Shortcut | Command name |
|---|---|---|
| 接受 inline 建议 | Tab |
editor.action.inlineSuggest.commit |
| 忽略建议 | Esc |
editor.action.inlineSuggest.hide |
| 显示下一条 inline 建议 | Alt+] |
editor.action.inlineSuggest.showNext |
| 显示上一条 inline 建议 | Alt+[ |
editor.action.inlineSuggest.showPrevious |
| 触发 inline 建议 | Alt+\ |
editor.action.inlineSuggest.trigger |
| 在单独面板显示更多建议 | Ctrl+Enter |
github.copilot.generate |
调试
一般两种调试方式, 打印和断点.
- Copilot 可以帮助自动生成打印代码, 根据上下文选用格式的打印或日志.
- Copilot 可以帮助修改已有代码结构, 提供方便的断点位置. 一些嵌套风格的代码难以打断点, Copilot 可以直接修改它们.
Copilot Labs 预置了以下功能:
- Debug, 生成调试代码, 例如打印, 断点, 以及其他调试代码.
检视
检视是相互的, 我们和 copilot 需要经常相互检视, 不要轻信快速生成的代码.
Copilot Labs 预置了以下功能:
- Fix bug, 直接修复它发现的 bug, 需要先保存好自己的代码, 仔细检视 Copilot 的修改.
- Make robust, 使代码更健壮, Copilot 会发现未处理的情况, 生成改进代码, 我们应该受其启发, 想的更缜密一些.
重构
Copilot Labs 预置了以下功能:
- Readable, 提高可读性, 真正的提高可读性, 而不是简单的格式化, 但是要务必小心的检视 Copilot 的修改.
- Clean, 使代码更简洁, 去除多余的代码.
- Chunk, 使代码更易于理解, 将代码分块, 将一个大函数分成多个小函数.
文档
Copilot Labs 预置了以下功能:
- Document, 生成文档, 例如函数注释, 以及其他文档.
使用 Custom 扩展 Copilot 边界
Custom不太起眼, 但它让 Copilot 具有无限可能. 我们可以将它理解为一种新的编程语言, 这种编程语言就是英语或者中文.
你可以通过 Custom 输入
-
移除注释代码
-
增加乘除的能力
-
改写为go
-
添加三角函数计算
-
添加微分计算, 中文这里不好用了, 使用support calculate differential, 在低温模式时, 没有靠谱答案, 高温模式时, 有几个离谱答案.
在日常工作中, 随时可以向 Copilot 提出自己的需求, 通过 Custom 能力, 可以让 Copilot 帮助完成许多想要的操作.
一些例子:
| prompts | 说明 |
|---|---|
generate the cmake file |
生成 cmake 文件 |
generate 10 test cases for tan() |
生成 10 个测试用例 |
format like google style |
格式化代码 |
考虑边界情况 |
考虑边界情况 |
确认释放内存 |
确认释放内存 |
Custom 用法充满想象力, 但有时也不那么靠谱, 建议使用前保存好代码, 然后好好检视它所作的修改.
获得更专业的建议
给 Copilot 的提示越清晰, 它给的建议越准确, 专业的提示可以获得更专业的建议. 许多不合适的代码既不影响代码编译, 也不影响业务运行, 但影响可读性, 可维护性, 扩展性, 复用, 这些特性也非常重要, 如果希望获得更专业的建议, 我们最好了解一些最佳实践的英文名称.
- 首先是使用可被理解的英文, 可以通过看开源项目学习英语.
- 命名约定, 命名是概念最基础的定义, 好的命名可以避免产生歧义, 避免阅读者陷入业务细节, 从而提高代码的可读性, 也是一种最佳实践.
- 通常只需要一个合理的变量名, Copilot 就能给出整段的靠谱建议.
- 设计模式列表, 设计模式是一种解决问题的模板, 针对不同问题合理取舍SOLID设计基本原则, 节省方案设计时间, 提高代码的质量.
- 只需要写出所需要的模式名称, Copilot 就能生成完整代码片段.
- 算法列表, 好的算法是用来解决一类问题的高度智慧结晶, 开发者需自行将具体问题抽象, 将数据抽象后输入到算法.
- 算法代码通常是通用的, 只需要写出算法名称, Copilot 就能生成算法代码片段, 并且 Copilot 总是能巧妙的将上下文的数据结构合理运用到算法中.
纯文本的建议
| en | zh |
|---|---|
| GitHub Copilot uses the OpenAI Codex to suggest code and entire functions in real-time, right from your editor. | GitHub Copilot 使用 OpenAI Codex 在编辑器中实时提供代码和整个函数的建议。 |
| Trained on billions of lines of code, GitHub Copilot turns natural language prompts into coding suggestions across dozens of languages. | 通过数十亿行代码的训练,GitHub Copilot 将自然语言提示转换为跨语言的编码建议。 |
| Don’t fly solo. Developers all over the world use GitHub Copilot to code faster, focus on business logic over boilerplate, and do what matters most: building great software. | 不要孤军奋战。世界各地的开发人员都在使用 GitHub Copilot 来更快地编码,专注于业务逻辑而不是样板代码,并且做最重要的事情:构建出色的软件。 |
| Focus on solving bigger problems. Spend less time creating boilerplate and repetitive code patterns, and more time on what matters: building great software. Write a comment describing the logic you want and GitHub Copilot will immediately suggest code to implement the solution. | 专注于解决更大的问题。花更少的时间创建样板和重复的代码模式,更多的时间在重要的事情上:构建出色的软件。编写描述您想要的逻辑的注释,GitHub Copilot 将立即提供代码以实现该解决方案。 |
| Get AI-based suggestions, just for you. GitHub Copilot shares recommendations based on the project’s context and style conventions. Quickly cycle through lines of code, complete function suggestions, and decide which to accept, reject, or edit. | 获得基于 AI 的建议,只为您。GitHub Copilot 根据项目的上下文和风格约定共享建议。快速循环代码行,完成函数建议,并决定接受,拒绝或编辑哪个。 |
| Code confidently in unfamiliar territory. Whether you’re working in a new language or framework, or just learning to code, GitHub Copilot can help you find your way. Tackle a bug, or learn how to use a new framework without spending most of your time spelunking through the docs or searching the web. | 在不熟悉的领域自信地编码。无论您是在新的语言或框架中工作,还是刚刚开始学习编码,GitHub Copilot 都可以帮助您找到自己的方式。解决 bug,或者在不花费大部分时间在文档或搜索引擎中寻找的情况下学习如何使用新框架。 |
这些翻译都由 Copilot 生成, 不能确定这些建议是基于模型生成, 还是基于翻译行为产生. 事实上你在表的en列中写的任何英语内容, 都可以被 Copilot 翻译(生成)到zh列中的内容.
设置项
客户端设置项
| 设置项 | 说明 | 备注 |
|---|---|---|
| temperature | 采样温度 | 0.0 - 1.0, 0.0 生成最常见的代码片段, 1.0 生成最不常见更随机的代码片段 |
| length | 生成代码建议的最大长度 | 默认 500 |
| inlineSuggestCount | 生成行内建议的数量 | 默认 3 |
| listCount | 生成建议的数量 | 默认 10 |
| top_p | 优先展示概率前 N 的建议 | 默认展示全部可能的建议 |
个人账户设置有两项设置, 一个是版权相关, 一个是隐私相关.
- 是否使用开源代码提供建议, 主要用于规避 Copilot 生成的代码片段中的版权问题, 避免开源协议限制.
- 是否允许使用个人的代码片段改进产品, 避免隐私泄露风险.
数据安全
Copilot 的信息收集
- 商用版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后立刻丢弃, 不保留任何代码片段
- 数据共享, GitHub, Microsoft, OpenAI
- 个人版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后, 根据个人 telemetry 设置, 保留或丢弃
- 代码片段包含, 正在编辑的代码, 关联文件, IDE 已打开文件, 库地址, 文件路径
- 数据共享, GitHub, Microsoft, OpenAI
- 代码数据保护, 1. 加密. 2. Copilot 团队相关的 Github/OpenAI 的部分员工可看. 3. 访问时需基于角色的访问控制和多因素验证
- 避免代码片段被使用(保留或训练), 1. 设置 2. 联系 Copilot 团队
- 私有代码是否会被使用? 不会.
- 是否会输出个人信息(姓名生日等)? 少见, 还在改进.
- 详细隐私声明
常见问题
- Copilot 的训练数据, 来自 Github 的公开库.
- Copilot 写的代码完美吗? 不一定.
- 可以为新平台写代码吗? 暂时能力有限.
- 如何更好的使用 Copilot? 拆分代码为小函数, 用自然语言描述函数的功能, 以及输入输出, 使用有具体意义的变量名和函数名.
- Copilot 生成的代码会有 bug 吗? 当然无法避免.
- Copilot 生成的代码可以直接使用吗? 不一定, 有时候需要修改.
- Copilot 生成的代码可以用于商业项目吗? 可以.
- Copilot 生成的代码属于 Copilot 的知识产权吗? 不属于.
- Copilot 是从训练集里拷贝的代码吗? Copilot 不拷贝代码, 极低概率会出现超过 150 行代码能匹配到训练集, 以下两种情况会出现
- 在上下文信息非常少时
- 是通用问题的解决方案
- 如何避免与公开代码重复, 设置filter
- 如何正确的使用 Copilot 生成的代码? 1. 自行测试/检视生成代码; 2. 不要在检视前自动编译或运行生成的代码.
- Copilot 是否在每种自然语言都有相同的表现? 最佳表现是英语.
- Copilot 是否会生成冒犯性内容? 已有过滤, 但是不排除可能出现.