Erfahrungsaustausch zur Nutzung des GitHub Copilot Agent-Modus
Categories:
Dieser Artikel fasst die Verwendung des GitHub Copilot Agent-Modus zusammen und teilt praktische Erfahrungen.
Voraussetzungen
- Verwenden Sie VSCode Insider;
- Installieren Sie das GitHub Copilot (Preview)-Plugin;
- Wählen Sie das Claude 3.7 Sonnet (Preview)-Modell, das bei der Codeerstellung hervorragend abschneidet. Andere Modelle punkten hingegen mit Geschwindigkeit, Multimodalität (z. B. Bilderkennung) und schlussfolgernden Fähigkeiten;
- Wählen Sie den Arbeitsmodus Agent.
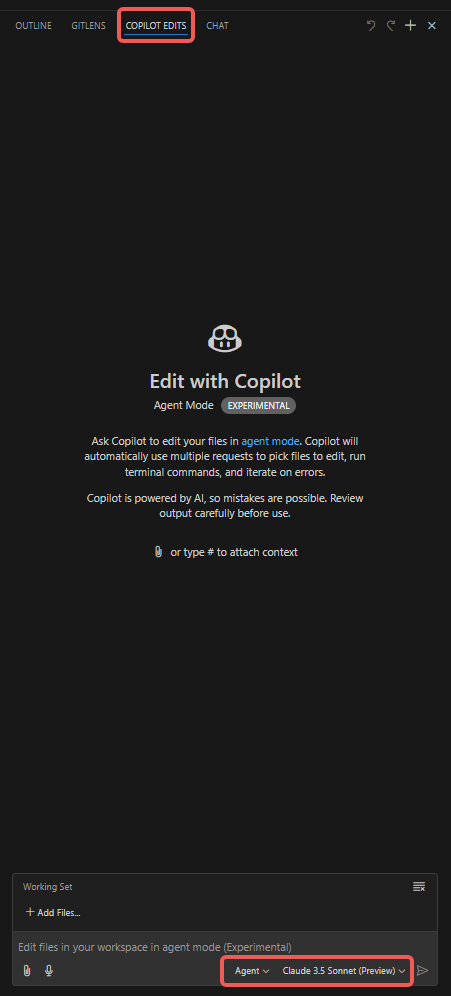
Bedienungsschritte
- Öffnen Sie die Registerkarte „Copilot Edits“;
- Fügen Sie Anhänge hinzu, wie „Codebase“, „Get Errors“, „Terminal Last Commands“ usw.;
- Fügen Sie „Working Set“-Dateien hinzu. Standardmäßig sind die derzeit geöffneten Dateien enthalten, andere Dateien können manuell ausgewählt werden (z. B. „Open Editors“);
- Fügen Sie „Instructions“ hinzu und geben Sie Hinweise ein, auf die der Copilot Agent besonders achten soll;
- Klicken Sie auf „Send“ und beginnen Sie das Gespräch, beobachten Sie das Verhalten des Agenten.
Weitere Hinweise
- VSCode kann durch Linting-Funktionen von Sprach-Plugins Error- oder Warning-Hinweise erzeugen, die der Agent automatisch zum Korrigieren von Code nutzen kann.
- Im Laufe des Gesprächs kann es passieren, dass die vom Agenten generierten Codeänderungen von den Erwartungen abweichen. Es wird empfohlen, jede Sitzung auf ein klares Thema zu fokussieren und zu vermeiden, dass das Gespräch zu lang wird; beenden Sie die aktuelle Sitzung nach Erreichen des kurzfristigen Ziels und starten Sie eine neue Aufgabe.
- Unter „Working Set“ bietet „Add Files“ die Option „Related Files“, die verwandte Dateien empfehlen kann.
- Achten Sie darauf, die Zeilenanzahl einzelner Code-Dateien zu kontrollieren, um einen zu schnellen Tokenverbrauch zu vermeiden.
- Es wird empfohlen, zuerst den Grundcode zu generieren und anschließend Testfälle zu schreiben, damit der Agent diese zum Debuggen und zur Selbstüberprüfung nutzen kann.
- Um den Änderungsumfang einzuschränken, können Sie in der settings.json folgende Konfiguration hinzufügen, die nur Änderungen an Dateien im angegebenen Verzeichnis erlaubt. Dient nur als Referenz:
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "Nur Dateien im Verzeichnis ./script/ ändern, andere Verzeichnisse nicht bearbeiten."
},
{
"text": "Wenn die Zielcodedatei mehr als 1000 Zeilen hat, sollten neue Funktionen in einer separaten Datei platziert werden, die durch Referenzierung aufgerufen wird; wenn die vorgenommenen Änderungen dazu führen, dass die Datei zu lang wird, kann diese Regel vorübergehend nicht strikt eingehalten werden."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "Testfälle in bestehenden Unit-Test-Dateien generieren."
},
{
"text": "Nach Codeänderungen unbedingt Testfälle ausführen, um sie zu validieren."
}
],
Häufige Probleme
Eingabebedarf liefert nicht den gewünschten Geschäftscode
Große Aufgaben müssen in kleinere Aufgaben unterteilt werden, wobei jede Sitzung nur eine kleine Aufgabe bearbeitet. Dies liegt daran, dass zu viel Kontext beim großen Modell zu einer Ablenkung der Aufmerksamkeit führt.
Der Kontext, der einer einzelnen Unterhaltung zugeführt wird, muss selbst abgewogen werden. Zu viel oder zu wenig kann dazu führen, dass die Anforderungen nicht verstanden werden.
Das DeepSeek-Modell hat das Problem der Aufmerksamkeitsverteilung gelöst, erfordert jedoch die Verwendung der Deepseek-API in Cursor. Die Effektivität hierbei ist unklar.
Langsame Reaktionszeiten
Es ist wichtig, das Tokenverbrauchs-Mechanismus zu verstehen. Eingabetoken sind günstig und zeitsparend, Ausgabetoken hingegen deutlich teurer und erheblich langsamer.
Wenn eine Code-Datei sehr groß ist, tatsächlich jedoch nur drei Codezeilen geändert werden müssen, kann der hohe Kontext und die große Ausgabe zu einem schnellen Tokenverbrauch und langsamen Reaktionen führen.
Daher ist es notwendig, die Dateigröße zu kontrollieren, keine großen Dateien und große Funktionen zu schreiben. Große Dateien und Funktionen rechtzeitig aufteilen und durch Referenzen aufrufen.
Geschäftsverständnisprobleme
Das Verständnis von Problemen hängt möglicherweise von den Kommentaren im Code und den Testdateien ab. Ausreichende Kommentare und Testfälle im Code helfen dem Copilot Agent, das Geschäft besser zu verstehen.
Die vom Agenten selbst generierten Geschäftscode-Dateien enthalten bereits ausreichend Kommentare. Durch die Überprüfung dieser Kommentare kann schnell beurteilt werden, ob der Agent die Anforderungen korrekt verstanden hat.
Viele generierte Codes erfordern längeres Debugging
Nach der Generierung des Grundcodes für eine bestimmte Funktion können zunächst Testfälle erstellt und anschließend die Geschäftslogik angepasst werden. So kann der Agent selbstständig debuggen und sich selbst validieren.
Der Agent fragt, ob das Ausführen von Testbefehlen erlaubt ist. Nach Abschluss der Ausführung liest er die Terminalausgabe, um zu prüfen, ob der Code korrekt ist. Falls nicht, passt er den Code basierend auf den Fehlermeldungen an. Dieser Zyklus wiederholt sich, bis die Tests bestanden sind.
Das bedeutet, dass man das Geschäft besser verstehen muss, und es sind nur wenige manuelle Schreibarbeiten erforderlich. Nur wenn weder die Testfall-Codes noch die Geschäfts-Codes korrekt sind, kann der Agent weder anhand der Anforderungen korrekte Testfälle noch anhand der Testfälle korrekten Geschäftscode schreiben. In solchen Fällen kann es zu längeren Debugging-Zeiten kommen.
Fazit
Verstehen Sie den Tokenverbrauchs-Mechanismus des großen Modells: Eingabekontext ist günstig und zeitsparend, ausgegebener Code ist teurer und langsamer. Nicht geänderte Codeabschnitte in Dateien werden möglicherweise ebenfalls als Ausgabe gezählt. Ein Indiz hierfür ist, dass auch viele nicht zu ändernde Codezeilen langsam ausgegeben werden.
Daher sollte die Größe einzelner Dateien so weit wie möglich kontrolliert werden. Man kann während der Nutzung das Reaktionsverhalten des Agenten beim Umgang mit großen und kleinen Dateien spüren. Dieser Unterschied ist sehr deutlich.