Condivisione delle esperienze sull'uso della modalità Agent di GitHub Copilot
Categories:
Questo articolo riassume come utilizzare la modalità Agent di GitHub Copilot e condivide esperienze pratiche.
Impostazioni preliminari
- Utilizzare VSCode Insider;
- Installare l’estensione GitHub Copilot (versione preview);
- Scegliere il modello Claude 3.7 Sonnet (versione preview), che si distingue per la scrittura di codice, mentre altri modelli presentano vantaggi in termini di velocità, multimodalità (ad esempio riconoscimento immagini) e capacità di ragionamento;
- Selezionare la modalità di lavoro Agent.
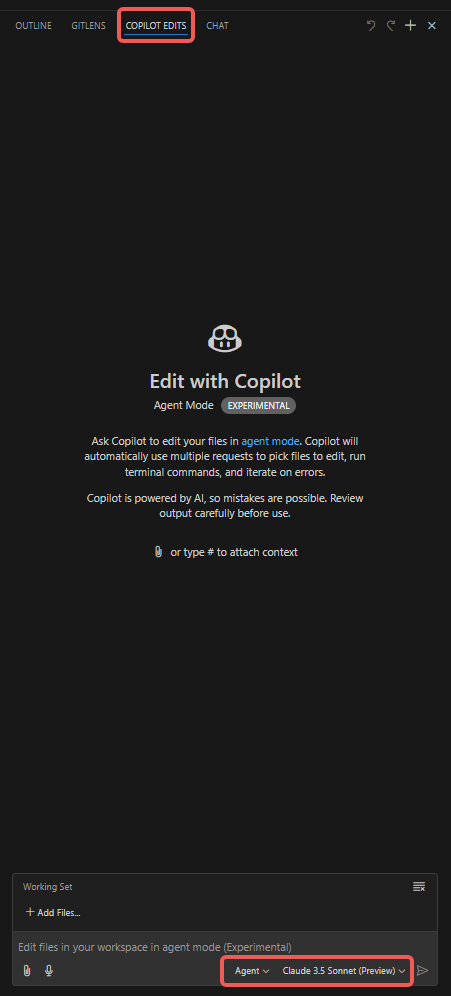
Passaggi operativi
- Aprire la scheda “Copilot Edits”;
- Aggiungere allegati come “Codebase”, “Get Errors”, “Terminal Last Commands”, ecc.;
- Aggiungere file a “Working Set”, che include per impostazione predefinita i file attualmente aperti, ma è possibile selezionare manualmente altri file (ad esempio “Open Editors”);
- Aggiungere “Instructions” inserendo prompt particolarmente importanti per Copilot Agent;
- Cliccare sul pulsante “Send” per avviare la conversazione e osservare le prestazioni dell’Agent.
Altre note
- VSCode può produrre avvisi Error o Warning tramite lint fornito dai plugin linguistici, e Agent può automaticamente correggere il codice in base a questi avvisi.
- Con il procedere della conversazione, le modifiche al codice generate dall’Agent potrebbero allontanarsi dagli obiettivi iniziali. Si consiglia di mantenere ogni sessione focalizzata su un obiettivo chiaro, evitando conversazioni troppo lunghe; terminare la sessione corrente dopo aver raggiunto un obiettivo a breve termine e avviare un nuovo compito.
- L’opzione “Add Files” sotto “Working Set” offre “Related Files” per raccomandare file correlati.
- Prestare attenzione al controllo del numero di righe per file di codice singolo per evitare un consumo eccessivo di token.
- Si consiglia di generare prima il codice di base, quindi creare casi di test, in modo che Agent possa eseguire il debug e l’autocorrezione in base ai risultati dei test.
- Per limitare l’ambito delle modifiche, è possibile aggiungere la seguente configurazione in settings.json, modificando solo i file nella directory specificata (riferimento opzionale):
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "Modifica solo i file nella directory ./script/, non modificare i file in altre directory."
},
{
"text": "Se il numero di righe del file di codice obiettivo supera le 1000 righe, si consiglia di posizionare le nuove funzioni in un nuovo file e richiamarle tramite riferimento; se le modifiche generate causano un file eccessivamente lungo, è possibile non seguire rigorosamente questa regola."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "Genera casi di test nei file di test unitari esistenti."
},
{
"text": "Dopo la modifica del codice, è necessario eseguire i casi di test per la verifica."
}
],
Problemi comuni
Non si ottiene il codice aziendale desiderato
È necessario suddividere i grandi compiti in compiti più piccoli, gestendo un piccolo compito per ogni sessione. Questo perché il contesto eccessivo può causare dispersione dell’attenzione nei grandi modelli.
Il contesto fornito a ogni singola conversazione richiede una propria valutazione, poiché troppo o troppo poco possono portare a una mancata comprensione dei requisiti.
Il modello DeepSeek ha risolto il problema della dispersione dell’attenzione, ma richiede l’uso dell’API Deepseek in cursor. Non è chiaro quanto efficace sia.
Problema di risposta lenta
È necessario comprendere il meccanismo di consumo dei token. L’input di token è economico e richiede meno tempo, mentre l’output di token è molto più costoso e decisamente più lento.
Se un file di codice è molto grande ma le righe che effettivamente necessitano di modifica sono solo tre, a causa del contesto eccessivo e dell’output elevato, il consumo di token sarà rapido e la risposta lenta.
Pertanto, è fondamentale controllare la dimensione dei file, evitando file e funzioni troppo grandi, suddividendoli tempestivamente e richiamandoli tramite riferimento.
Problema di comprensione aziendale
La comprensione potrebbe dipendere in parte dai commenti nel codice e dai file di test. Integrare commenti sufficienti e casi di test nel codice aiuta Copilot Agent a comprendere meglio l’azienda.
Il codice aziendale generato da Agent stesso contiene commenti sufficienti; esaminando questi commenti è possibile rapidamente determinare se Agent ha compreso correttamente i requisiti.
Generazione di una grande quantità di codice che richiede un lungo debug
Si può considerare di generare prima il codice di base per una caratteristica, quindi creare casi di test, e infine regolare la logica aziendale, consentendo così ad Agent di eseguire autonomamente il debug e l’autoverifica.
Agent chiederà se è consentito eseguire comandi di test; dopo l’esecuzione, leggerà autonomamente l’output del terminale per determinare la correttezza del codice. Se non è corretto, modificherà il codice in base alle informazioni di errore. Questo ciclo continua fino al superamento dei test.
In altre parole, è necessario comprendere maggiormente l’azienda; non è spesso necessario scrivere manualmente. Se né il codice del caso di test né il codice aziendale sono corretti, Agent non può scrivere casi di test corretti in base all’azienda né scrivere codice aziendale corretto in base ai casi di test. Solo in questo caso si verificherà un debug prolungato.
Sommario
Comprendere il meccanismo di consumo dei token nei grandi modelli: il contesto in input è economico, mentre il codice in output è costoso e più lento. Le parti del file non modificate potrebbero essere conteggiate come output; la prova è che anche molto codice che non richiede modifiche viene lentamente prodotto.
Pertanto, è necessario controllare la dimensione dei singoli file, sperimentando nella pratica la differenza di velocità di risposta di Agent quando gestisce file grandi e piccoli, una differenza molto evidente.