思维工具
一、基础逻辑思维方法
-
归纳与演绎
- 归纳:从个别案例总结普遍规律(如从“黑马、白马”归纳出“马”的概念)。
- 演绎:从普遍规律推导具体结论(如根据“马”的定义推导出“黑马”“白马”)。
- 应用场景:科学研究、数据分析、制定规则。
-
分析与综合
- 分析:将整体拆解为部分研究(如分解光的波粒二象性)。
- 综合:将部分整合为整体理解(如结合光的波动性和粒子性提出新理论)。
- 应用场景:复杂问题拆解、系统设计。
-
因果推理
- 正推:从原因推断结果(如“下雨导致地面湿”)。
- 逆推:从结果反推原因(如“地面湿”推断“可能下雨”)。
- 应用场景:故障排查、逻辑推理。
二、结构化思维工具
-
黄金圈法则(Why-How-What)
- Why:核心目标(为什么做)。
- How:实现路径(如何做)。
- What:具体行动(做什么)。
- 应用场景:战略规划、演讲表达(如苹果公司“我们坚信创新驱动世界”)。
-
SCQA 模型
- S(Situation):背景情景。
- C(Complication):冲突或问题。
- Q(Question):提出核心问题。
- A(Answer):解决方案。
- 应用场景:演讲、报告、提案的结构化表达。
-
金字塔原理
- 结构:中心论点 → 分论点 → 支持细节。
- 应用场景:写作、汇报、逻辑表达(如“数字化转型是趋势”→ 市场、客户、竞争三方面论证)。
-
5W1H 分析法
- What:做什么?
- Why:为什么做?
- Who:谁来做?
- Where:在哪里做?
- When:何时做?
- How:如何做?
- 应用场景:项目计划、任务分解(如自媒体运营的详细规划)。
三、决策与问题解决工具
-
SWOT 分析
- 优势(Strengths):内部强项。
- 劣势(Weaknesses):内部弱点。
- 机会(Opportunities):外部机会。
- 威胁(Threats):外部风险。
- 应用场景:商业战略、个人职业规划。
-
10/10/10 法则
- 提问:从三个时间维度(10 分钟、10 个月、10 年后)评估决策的影响。
- 应用场景:短期与长期决策平衡(如是否换工作、投资)。
-
鱼骨图(因果图)
- 结构:将问题(鱼头)与可能原因(鱼骨分支)可视化。
- 应用场景:根因分析(如产品质量问题、工作低效原因)。
-
PDCA 循环(戴明环)
- Plan:计划。
- Do:执行。
- Check:检查结果。
- Act:改进并固化。
- 应用场景:流程优化、持续改进(如自媒体内容迭代)。
四、学习与沟通工具
-
费曼学习法
- 步骤:
- 选择知识点;
- 假设教学;
- 纠错与简化;
- 用通俗语言复述。
- 应用场景:知识内化、教学准备。
- 步骤:
-
思维导图
- 特点:以中心主题发散分支,可视化关联。
- 应用场景:笔记整理、创意发散(如策划活动)。
-
SCAMPER 法则(创新思维)
- S(Substitute):替代。
- C(Combine):结合。
- A(Adapt):改造。
- M(Modify/Magnify):调整/放大。
- P(Purpose):改变用途。
- E(Eliminate):消除。
- R(Rearrange/Reverse):重组/反转。
- 应用场景:产品创新、方案优化。
-
六顶思考帽
- 角色分工:
- 白帽(数据)、红帽(情感)、黑帽(风险)、黄帽(价值)、绿帽(创新)、蓝帽(控制)。
- 应用场景:团队头脑风暴、多角度决策。
- 角色分工:
五、系统与创新思维
-
乔哈里视窗
- 四区域模型:
- 开放区(已知于己和他人)。
- 隐秘区(己知但他人未知)。
- 盲目区(未知于己但他人知)。
- 未知区(所有人未知)。
- 应用场景:团队沟通、自我认知提升。
- 四区域模型:
-
上游思维(根本原因分析)
- 核心:不解决表象问题,而追溯问题根源。
- 应用场景:长期问题解决(如杜威通过清理蚊虫滋生地解决蚊患)。
-
二八法则(帕累托原则)
- 原理:20%的原因导致 80%的结果。
- 应用场景:资源分配(如聚焦 20%的关键客户)。
六、高效行动工具
-
复盘法
- 步骤:回顾行动、分析得失、提炼经验。
-
最小可行性产品(Minimum Viable Product, MVP)
- 核心:快速推出基础版本,验证需求后迭代。
- 应用场景:产品开发、创业验证。
- 5Why 分析法
- 方法:连续追问“为什么”直至找到根本原因。
- 应用场景:故障排查、习惯养成(如分析加班原因)。
七、其他实用工具
- 九宫格思维法:中心问题发散至 9 个方向,避免过度发散。
- 思维导图+曼陀罗矩阵:结合视觉化与结构化思考。
- 黄金时间圈:区分“重要-紧急”四象限,管理时间优先级。
总结
这些工具可根据具体场景灵活组合使用:
- 学习:费曼法、思维导图、刻意练习。
- 决策:黄金圈、SWOT、10/10/10 法则。
- 沟通:SCQA、六顶思考帽、乔哈里视窗。
- 创新:SCAMPER、上游思维、5W1H。
通过结合多种工具,可以提升思维效率,突破认知局限,更高效地解决问题和实现目标。
工具
为AdguardHome增加分流能力
开源地址: https://github.com/AdGuardPrivate/AdGuardPrivate
AdGuardHome 不带分流规则, 只能手写, 或则配置一个 upstream-file, 算是其痛点之一.
开发支持分流规则这个特性花了不少时间, 也测试了比较久, 总算稳定了.
有了分流规则, 就不再需要在 AdguardHome 前置 SmartDNS, 一个 AdguardPrivate 就齐活.
当然现在分流能力仅支持分 AB 两路, 即一部分走 A 上游群, 一部分走 B 上游群. 如果要做更灵活的分流支持, 开发难度会大一些, 实际的分流代码逻辑一部分在 adguardhome 中, 另外一部分在 dnsproxy 中. 两路不能满足需求的话, 可以 fork 了自己尝试做做.
有使用问题或建议可以提 issue, 目前主要针对特定地区的使用做一些改良.

广告拦截新选择--AdGuardPrivate
AdGuardPrivate 是一款专注于网络隐私保护与广告拦截的 DNS 服务工具,基于开源项目 AdGuard Home 二次开发,通过智能流量分析和过滤技术,为用户提供安全、高效的上网环境。以下是其主要功能与特点:
核心功能:广告拦截与隐私保护
- 广告拦截:通过 DNS 层面拦截网页广告(如横幅、弹窗、视频广告等)及移动应用内广告,提升浏览速度和设备性能。
- 隐私防护:阻止跟踪器、社交网络插件和隐私窃取请求,防止用户行为数据被收集,同时拦截恶意网站、钓鱼链接和恶意软件。
- DNS 防污染:通过加密 DNS(支持 DoT、DoH、HTTP/3)防止流量劫持,确保域名解析的准确性和安全性。
进阶特性:定制化与优化
- 自定义规则:支持用户添加第三方黑白名单或自定义过滤规则,灵活控制特定应用、网站或游戏的访问权限。
- 智能解析:可配置局域网设备的友好域名解析(如 NAS 或企业服务器),简化网络管理。
- 统计分析:提供详细的请求日志、拦截统计和 72 小时查询记录,帮助用户监控网络使用情况。
家庭与企业场景支持
- 家长控制:可屏蔽成人网站和游戏,管理家庭成员的上网时间,保护未成年人。
- 企业级部署:支持分布式服务器负载均衡,优化大陆地区的访问体验,并通过阿里云节点提供稳定服务。
平台兼容性与服务模式
- 跨平台支持:兼容多种操作系统,无需额外软件,仅需配置加密 DNS 即可使用。
- 服务模式:
- 免费公共服务:提供基础广告拦截与安全规则,但可能存在误拦截问题。
- 付费私有服务:增强功能包括自定义解析、权威解析、设备分 ID 记录上网行为等,适合个性化需求。
技术优势与局限性
- 优势:全设备覆盖、零额外功耗,降低无效数据加载,适合移动设备续航优化。
- 局限性:拦截精度低于浏览器插件,无法实现 HTTPS 内容的深度过滤(如 MITM 方案)。
- 应用场景示例
- 个人用户:通过 AdGuardPrivate 阻止移动应用内广告,提升应用体验。
- 家庭用户:通过路由器部署 AdGuardPrivate,拦截全家设备的广告,并限制儿童访问不当内容。
- 企业网络:结合自定义规则屏蔽娱乐类网站,提升员工工作效率,同时保护内部数据安全。
使用 curl 获取 DNS 结果
本文介绍两种利用 curl 获取 DNS 查询结果的方法:
- DNS JSON 格式
- DNS Wire Format 格式
1. DNS JSON 格式查询
返回 JSON 格式的 DNS 响应,便于解析。
curl -H 'accept: application/dns-json' "https://dns.google/resolve?name=baidu.com&type=A" | jq .
Cloudflare
curl -H 'accept: application/dns-json' 'https://cloudflare-dns.com/dns-query?name=baidu.com&type=A' | jq .
Aliyun
curl -H "accept: application/dns-json" "https://223.5.5.5/resolve?name=baidu.com&type=1" | jq .
dns.pub
curl -H 'accept: application/dns-json' 'https://doh.dns.pub/dns-query?name=baidu.com&type=A' | jq .
AdGuard Private DNS
# 暂不受支持
2. DNS Wire Format 格式查询
返回二进制格式的 DNS 响应,需要进一步解析。
curl -H 'accept: application/dns-message' 'https://dns.google/dns-query?dns=q80BAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB' | hexdump -c
Cloudflare
curl -H 'accept: application/dns-message' 'https://cloudflare-dns.com/dns-query?dns=q80BAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB' | hexdump -c
Aliyun
curl -H 'accept: application/dns-message' "https://dns.alidns.com/dns-query?dns=P8QBAAABAAAAAAAABWJhaWR1A2NvbQAAAQAB" | hexdump -c
dns.pub
curl -H 'accept: application/dns-message' 'https://doh.dns.pub/dns-query?dns=q80BAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB' | hexdump -c
AdGuard Private DNS
curl -H 'accept: application/dns-message' 'https://public0.adguardprivate.com/dns-query?dns=q80BAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB' | hexdump -c
使用 Python 解析 DNS 响应
# pip install dnspython
# pip install requests
# 解析 JSON 格式响应
import json
import requests
def query_dns_json(domain="example.com", type="A"):
"""使用 JSON 格式查询 DNS"""
url = "https://dns.google/resolve"
params = {"name": domain, "type": type}
headers = {"accept": "application/dns-json"}
response = requests.get(url, params=params, headers=headers)
return json.dumps(response.json(), indent=2)
# 解析 Wire Format 响应
def query_dns_wire(domain="example.com"):
"""使用 Wire Format 格式查询 DNS"""
import dns.message
import requests
import base64
# 创建DNS查询消息
query = dns.message.make_query(domain, 'A')
wire_format = query.to_wire()
dns_query = base64.b64encode(wire_format).decode('utf-8')
# 发送请求
url = "https://dns.google/dns-query"
params = {"dns": dns_query}
headers = {"accept": "application/dns-message"}
response = requests.get(url, params=params, headers=headers)
dns_response = dns.message.from_wire(response.content)
return str(dns_response)
if __name__ == "__main__":
print("JSON格式查询结果:")
print(query_dns_json())
print("\nWire Format查询结果:")
print(query_dns_wire())
生成 DNS Wire Format Base64 编码的数据
# pip install dnspython
import base64
import dns.message
import dns.rdatatype
# 创建一个DNS查询消息
query = dns.message.make_query('example.com', dns.rdatatype.A)
# 将消息转换为Wire Format
wire_format = query.to_wire()
# 转为base64
wire_format_base64 = base64.b64encode(wire_format).decode('utf-8')
# 打印
print(wire_format_base64)
如何使用必应国际版
有些搜索引擎不思进取,能搜到的有价值的内容越来越少,广告却越来越多。相信不少人都已逐渐放弃这类搜索引擎,转而使用必应(bing.com)。
但必应有多个版本:
- cn.bing.com 是中国版,搜索结果经过审查。
- 国内版:主要搜索中文内容。

- 国际版:同时支持搜索中文和英文内容。

- 国内版:主要搜索中文内容。
- www.bing.com 这是真正的国际版,搜索结果没有中国大陆的审查,可以搜索到更多“你懂的”内容。

这三个版本的搜索结果会有所区别。对于具备英文阅读能力的用户,强烈推荐使用国际版,能获取到更有价值的资料。
我就不详细展开真国际版搜索内容的差异了,有兴趣的朋友可以自行尝试。
真国际版还提供 Microsoft Copilot 的入口,类似于 ChatGPT 的功能,可以帮你总结搜索结果。虽然有使用频次限制,但正常使用是足够的。
国内版和国际版的切换没有难度,这里主要介绍如何使用必应真正的国际版。
相信不少人在设置里折腾了很久,但还是无法使用国际版,这可能是方向错了。
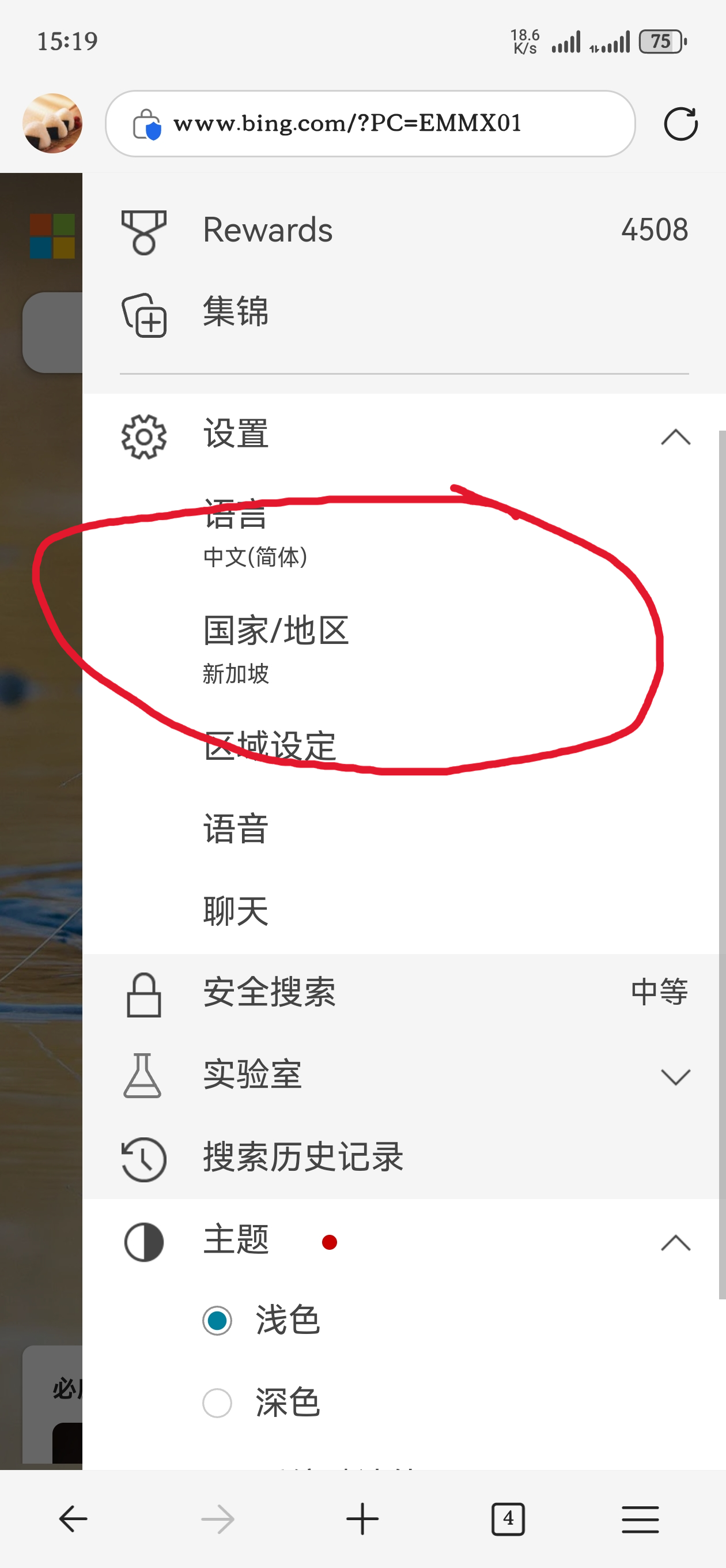
真正的限制在于 DNS。DNS 可以根据请求者的所在地域,给出不同的解析结果。例如,山东和河南请求 qq.com 的 IP 地址可能不一样。通常,DNS 会返回在地理位置上更靠近的服务器 IP。
因此,如果你想使用国际版,可以尝试将 DNS 更换为 Google 的 tls://dns.google 或者 Cloudflare 的 tls://one.one.one.one。
这里只提供了两个 DNS 服务商的加密 DNS 地址,没有提供纯 IP 的 DNS,因为纯 IP 的海外 DNS 很容易被劫持,分享 8.8.8.8 和 1.1.1.1 毫无意义。
DNS 的设置方法可以参考 如何配置 DNS 加密。
注意,最简单的使用国际版必应的方法是使用加密 DNS,也有其他方法,本文不展开。
如果一个 DNS 不可用,可以依次尝试以下几个设置:
tls://dns.googletls://one.one.one.onetls://8.8.8.8tls://8.8.4.4tls://1.1.1.1tls://1.0.0.1
通常会有两个能连接成功。如果全部无法连接,那只能寻找其他方法了。
微信读书体验分享
免费读书方案有很多, 但是微信读书的确是体验做的较好的一个. 希望免费读书的可以看 zlibrary.
这里主要分享微信读书的使用体验, 以及一些辅助工具, 如有任何侵权, 请联系我删除: [email protected]
微信读书自动打卡刷时长
只为便宜一点买微信读书会员.
本文档可能已过时, 最新可以访问开源地址: https://github.com/jqknono/weread-challenge-selenium
微信读书规则
- 离线阅读计入总时长, 但需要联网上报
- 网页版, 墨水屏, 小程序, 听书, 有声书收听都计入总时长
- 对单次自动阅读或收听时长过长的行为, 平台将结合用户行为特征判断, 过长部分不计入总时长
- 当日阅读超过5 分钟才算作有效阅读天数
- 付费 5 元立即获得 2 天会员, 后续 30 日内打卡 29 天, 读书时长超过 30 小时, 可获得 30 天会员和 30 书币
- 付费 50 元立即获得 30 天会员, 后续 365 日内打卡 360 天, 读书时长超过 300 小时, 可获得 365 天会员和 500 书币
根据实际操作, 还有如下未明确说明的特点:
- 第 29 日打卡后立即获得读书会员奖励, 并可立即开始下一轮挑战会员打卡, 无需等待第 31 日开始下一轮挑战, 第 29 日的打卡既算上一轮的打卡, 也算下一轮的打卡.
- 除第一轮需 29 日外, 后续每 28 日即可获得 32 日会员, 1+28*13=365, 一年可完成 13 轮, 花费 65 元, 获得 32*13=416 天会员和 390 书币.
- 更划算的仍然是年卡挑战会员, 但周期更长, 风险更大.
工具特性
- 使用有头浏览器
- 支持本地浏览器和远程浏览器
- 随机浏览器宽度和高度
- 支持等待登录
- 支持登录二维码刷新
- 支持保存 cookies
- 支持加载 cookies
- 支持选择最近阅读的第 X 本书开始阅读
- 默认随机选择一本书开始阅读
- 支持自动阅读
- 支持跳到下一章
- 支持读完跳回第一章继续阅读
- 支持选择阅读速度
- 随机单页阅读时间
- 随机翻页时间
- 每分钟截图当前界面
- 支持日志
- 支持定时任务
- 支持设置阅读时间
- 支持邮件通知
- 多平台支持:
linux | windows | macos
- 支持浏览器:
chrome | MicrosoftEdge | firefox - 支持多用户
- 异常时强制刷新
- 使用统计
Linux
直接运行
# 安装nodejs
sudo apt install nodejs
# 老旧版本的 nodejs 需要安装 npm
sudo apt install npm
# 创建运行文件夹
mkdir -p $HOME/Documents/weread-challenge
cd $HOME/Documents/weread-challenge
# 安装依赖
npm install selenium-webdriver
# 下载脚本
wget https://storage1.techfetch.dev/weread-challenge/weread-challenge.js -O weread-challenge.js
# 通过环境变量设置运行参数
export WEREAD_BROWSER="chrome"
# 运行
WEREAD_BROWSER="chrome" node weread-challenge.js
如需邮件通知, 需安装 nodemailer:
npm install nodemailer
Docker Compose 运行
services:
app:
image: jqknono/weread-challenge:latest
pull_policy: always
environment:
- WEREAD_REMOTE_BROWSER=http://selenium:4444
- WEREAD_DURATION=68
volumes:
- ./data:/app/data
depends_on:
selenium:
condition: service_healthy
selenium:
image: selenium/standalone-chrome:4.26
pull_policy: if_not_present
shm_size: 2gb
volumes:
- /var/run/docker.sock:/var/run/docker.sock
environment:
- SE_ENABLE_TRACING=false
- SE_BIND_HOST=false
- SE_JAVA_DISABLE_HOSTNAME_VERIFICATION=false
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:4444/wd/hub/status"]
interval: 5s
timeout: 60s
retries: 10
保存为 docker-compose.yml, 运行 docker compose up -d.
首次启动后, 需微信扫描二维码登录, 二维码保存在 ./data/login.png
Docker 运行
# run selenium standalone
docker run --restart always -d --name selenium-live \
-v /var/run/docker.sock:/var/run/docker.sock \
--shm-size="2g" \
-p 4444:4444 \
-p 7900:7900 \
-e SE_ENABLE_TRACING=false \
-e SE_BIND_HOST=false \
-e SE_JAVA_DISABLE_HOSTNAME_VERIFICATION=false \
-e SE_NODE_MAX_INSTANCES=10 \
-e SE_NODE_MAX_SESSIONS=10 \
-e SE_NODE_OVERRIDE_MAX_SESSIONS=true \
selenium/standalone-chrome:4.26
# run weread-challenge
docker run --rm --name user-read \
-v $HOME/weread-challenge/user/data:/app/data \
-e WEREAD_REMOTE_BROWSER=http://172.17.0.2:4444 \
-e WEREAD_DURATION=68 \
weread-challenge:latest
# add another user
docker run --rm --name user2-read \
-v $HOME/weread-challenge/user2/data:/app/data \
-e WEREAD_REMOTE_BROWSER=http://172.17.0.2:4444 \
-e WEREAD_DURATION=68 \
weread-challenge:latest
首次启动后, 需微信扫描二维码登录, 二维码保存在 ./data/login.png
创建定时任务
docker-compose 方式
WORKDIR=$HOME/weread-challenge
mkdir -p $WORKDIR
cd $WORKDIR
cat > $WORKDIR/docker-compose.yml <<EOF
services:
app:
image: jqknono/weread-challenge:latest
pull_policy: always
environment:
- WEREAD_REMOTE_BROWSER=http://selenium:4444
- WEREAD_DURATION=68
volumes:
- ./data:/app/data
depends_on:
selenium:
condition: service_healthy
selenium:
image: selenium/standalone-chrome:4.26
pull_policy: if_not_present
shm_size: 2gb
volumes:
- /var/run/docker.sock:/var/run/docker.sock
environment:
- SE_ENABLE_TRACING=false
- SE_BIND_HOST=false
- SE_JAVA_DISABLE_HOSTNAME_VERIFICATION=false
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:4444/wd/hub/status"]
interval: 5s
timeout: 60s
retries: 10
EOF
# 首次启动后, 需微信扫描二维码登录, 二维码保存在 $HOME/weread-challenge/data/login.png
# 每天早上 7 点启动, 阅读68分钟
(crontab -l 2>/dev/null; echo "00 07 * * * cd $WORKDIR && docker compose up -d") | crontab -
docker 方式
# 启动浏览器
docker run --restart always -d --name selenium-live \
-v /var/run/docker.sock:/var/run/docker.sock \
--shm-size="2g" \
-p 4444:4444 \
-p 7900:7900 \
-e SE_ENABLE_TRACING=false \
-e SE_BIND_HOST=false \
-e SE_JAVA_DISABLE_HOSTNAME_VERIFICATION=false \
-e SE_NODE_MAX_INSTANCES=3 \
-e SE_NODE_MAX_SESSIONS=3 \
-e SE_NODE_OVERRIDE_MAX_SESSIONS=true \
-e SE_SESSION_REQUEST_TIMEOUT=10 \
-e SE_SESSION_RETRY_INTERVAL=3 \
selenium/standalone-chrome:4.26
WEREAD_USER="user"
mkdir -p $HOME/weread-challenge/$WEREAD_USER/data
# Get container IP
Selenium_IP=$(docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' selenium-live)
# 首次启动后, 需微信扫描二维码登录, 二维码保存在 $HOME/weread-challenge/$WEREAD_USER/data/login.png
# 每天早上 7 点启动, 阅读68分钟
(crontab -l 2>/dev/null; echo "00 07 * * * docker run --rm --name ${WEREAD_USER}-read -v $HOME/weread-challenge/${WEREAD_USER}/data:/app/data -e WEREAD_REMOTE_BROWSER=http://${Selenium_IP}:4444 -e WEREAD_DURATION=68 -e WEREAD_USER=${WEREAD_USER} jqknono/weread-challenge:latest") | crontab -
Windows
# 安装nodejs
winget install -e --id Node.js.Node.js
# 创建运行文件夹
mkdir -p $HOME/Documents/weread-challenge
cd $HOME/Documents/weread-challenge
# 安装依赖
npm install selenium-webdriver
# 下载脚本powershell
Invoke-WebRequest -Uri https://storage1.techfetch.dev/weread-challenge/weread-challenge.js -OutFile weread-challenge.js
# 通过环境变量设置运行参数
$env:WEREAD_BROWSER="MicrosoftEdge"
# 运行
node weread-challenge.js
Docker 运行同 Linux.
MacOS
# 安装nodejs
brew install node
# 创建运行文件夹
mkdir -p $HOME/Documents/weread-challenge
cd $HOME/Documents/weread-challenge
# 安装依赖
npm install selenium-webdriver
# 下载脚本
wget https://storage1.techfetch.dev/weread-challenge/weread-challenge.js -O weread-challenge.js
# 通过环境变量设置运行参数
export WEREAD_BROWSER="chrome"
# 运行
node weread-challenge.js
Docker 运行同 Linux.
多用户支持
# 启动浏览器
docker run --restart always -d --name selenium-live \
-v /var/run/docker.sock:/var/run/docker.sock \
--shm-size="2g" \
-p 4444:4444 \
-p 7900:7900 \
-e SE_ENABLE_TRACING=false \
-e SE_BIND_HOST=false \
-e SE_JAVA_DISABLE_HOSTNAME_VERIFICATION=false \
-e SE_NODE_MAX_INSTANCES=10 \
-e SE_NODE_MAX_SESSIONS=10 \
-e SE_NODE_OVERRIDE_MAX_SESSIONS=true \
selenium/standalone-chrome:4.26
WEREAD_USER1="user1"
WEREAD_USER2="user2"
mkdir -p $HOME/weread-challenge/$WEREAD_USER1/data
mkdir -p $HOME/weread-challenge/$WEREAD_USER2/data
# Get container IP
Selenium_IP=$(docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' selenium-live)
# 首次启动后, 需微信扫描二维码登录, 二维码保存在:
# /$HOME/weread-challenge/${WEREAD_USER1}/data/login.png
# /$HOME/weread-challenge/${WEREAD_USER2}/data/login.png
# 每天早上 7 点启动, 阅读68分钟
(crontab -l 2>/dev/null; echo "00 07 * * * docker run --rm --name ${WEREAD_USER1}-read -v $HOME/weread-challenge/${WEREAD_USER1}/data:/app/data -e WEREAD_REMOTE_BROWSER=http://${Selenium_IP}:4444 -e WEREAD_DURATION=68 -e WEREAD_USER=${WEREAD_USER1} jqknono/weread-challenge:latest") | crontab -
(crontab -l 2>/dev/null; echo "00 07 * * * docker run --rm --name ${WEREAD_USER2}-read -v $HOME/weread-challenge/${WEREAD_USER2}/data:/app/data -e WEREAD_REMOTE_BROWSER=http://${Selenium_IP}:4444 -e WEREAD_DURATION=68 -e WEREAD_USER=${WEREAD_USER2} jqknono/weread-challenge:latest") | crontab -
可配置项
| 环境变量 | 默认值 | 可选值 | 说明 |
|---|---|---|---|
WEREAD_USER |
weread-default |
- | 用户标识 |
WEREAD_REMOTE_BROWSER |
"" | - | 远程浏览器地址 |
WEREAD_DURATION |
10 |
- | 阅读时长 |
WEREAD_SPEED |
slow |
slow,normal,fast |
阅读速度 |
WEREAD_SELECTION |
random |
[0-4] | 选择阅读的书籍 |
WEREAD_BROWSER |
chrome |
chrome,MicrosoftEdge,firefox |
浏览器 |
ENABLE_EMAIL |
false |
true,false |
邮件通知 |
EMAIL_SMTP |
"" | - | 邮箱 SMTP 服务器 |
EMAIL_USER |
"" | - | 邮箱用户名 |
EMAIL_PASS |
"" | - | 邮箱密码 |
EMAIL_TO |
"" | - | 收件人 |
WEREAD_AGREE_TERMS |
true |
true,false |
隐私同意条款 |
注意事项
- 28 日刷满 30 小时, 需每日至少 65 分钟, 而不是每日 60 分钟.
- 微信读书统计可能会漏数分钟, 期望每日获得 65 分钟, 建议调整阅读时长到 68 分钟
- 网页扫码登录 cookies 有效期为 30 天, 30 天后需重新扫码登录, 适合月挑战会员
- 邮件通知可能被识别为垃圾邮件, 建议在收件方添加白名单
- 本项目仅供学习交流使用, 请勿用于商业用途, 请勿用于违法用途
- 如存在可能的侵权, 请联系
[email protected], 本项目会立即删除
隐私政策
- 隐私获取
- 本项目搜集使用者的
cookies部分信息, 以用于使用者统计和展示. - 搜集使用者的使用信息, 包含:
用户名称 | 首次使用时间 | 最近使用时间 | 总使用次数 | 浏览器类型 | 操作系统类别 | 阅读时长设置 | 异常退出原因 - 如不希望被搜集任何信息, 可设置启动参数
WEREAD_AGREE_TERMS=false
- 本项目搜集使用者的
- 风险提示
cookies可用于微信读书网页登录, 登录后可以执行书架操作, 但本工具不会使用搜集的信息进行登录操作.- 腾讯保护机制确保异常登录时, 手机客户端将收到风险提示, 可在手机客户端
设置->登录设备中确认登录设备. - 本工具纯 js 实现, 容易反混淆和扩展, 第三方可以继续开发. 即使信任本工具, 也应在使用自动化工具时, 经常确认登录设备, 避免书架被恶意操作.
参考
关闭独显以省电
这篇文分享给台式机很少关机, 经常远程回家中的台式机上工作的朋友.
我的主力工作机和游戏机是同一台机器, 显示屏是 4K 144Hz, 日常都是开着独显, 普通操作显示都会更顺滑一些, 但是功耗也是明显更大.
以下截图里的功率同时带着一个 J4125 小主机, 日常功耗在 18w 上下, 因此结论可能有不准确的地方
不开游戏, 在桌面快速滑动鼠标的峰值功率可以到192w
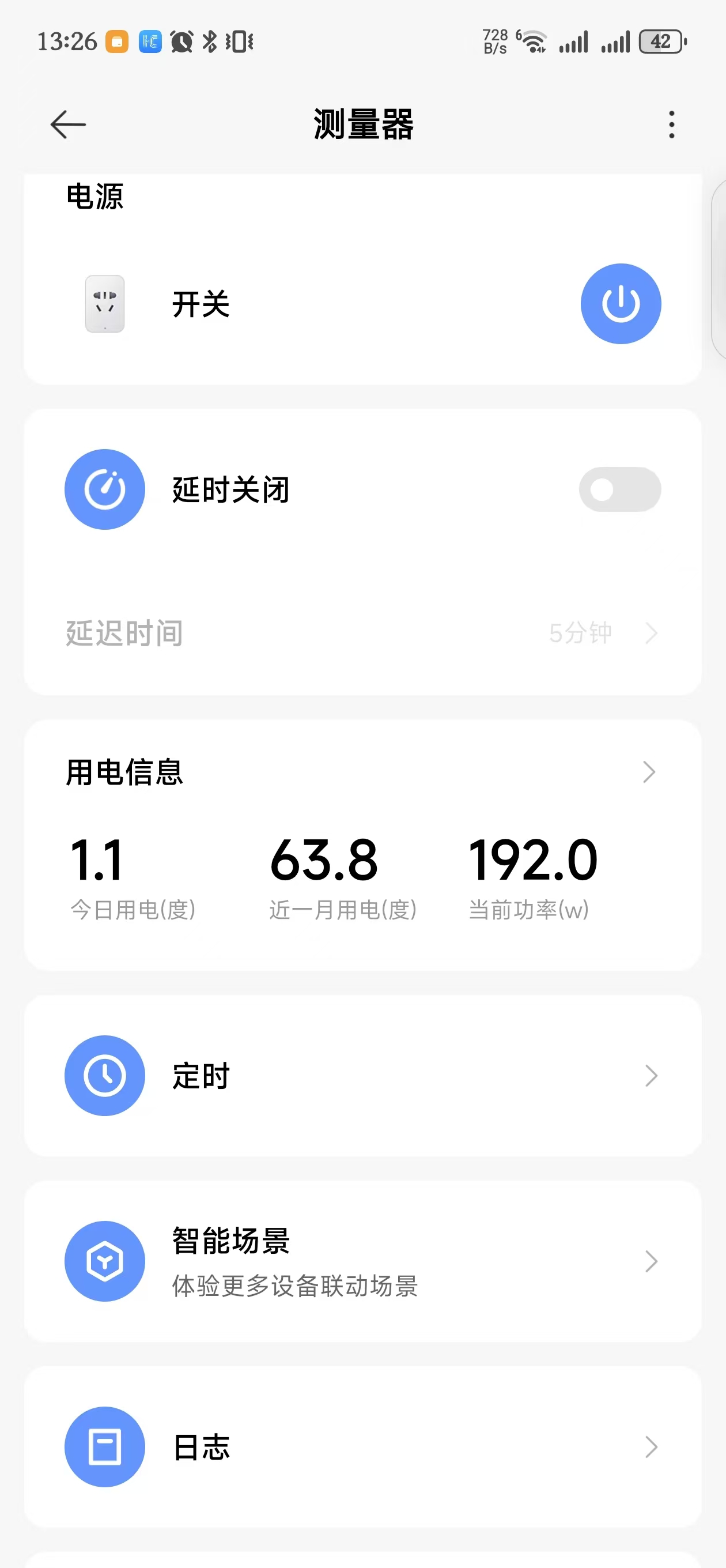
关闭独显后, 刷新率降到 60Hz, 峰值功率降到120w上下.
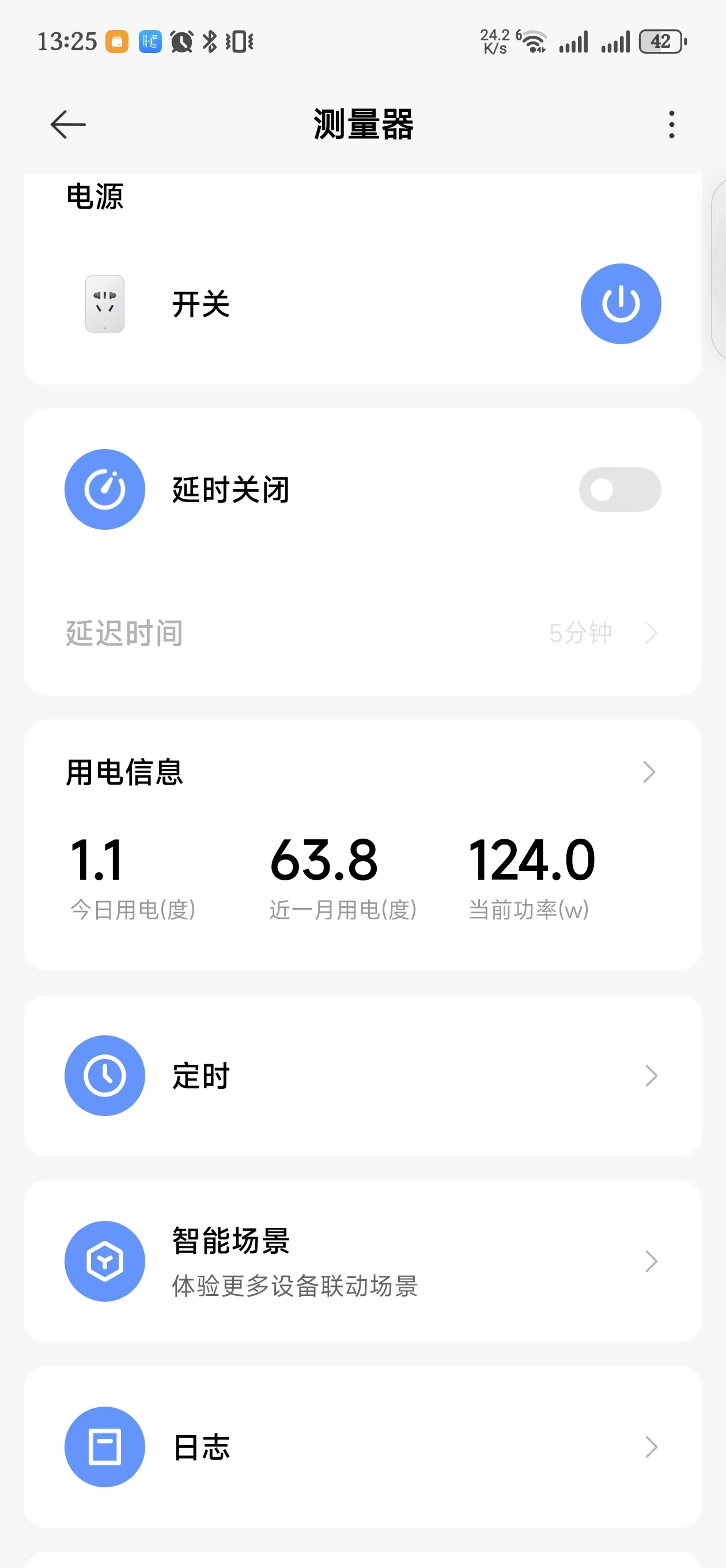
在外隧道回家工作是使用的腾讯的一个入门主机, 带宽较小, 远端刷新率只有 30hz, 这种情况用独显是没有意义, 可以考虑切换到集显.
多数时候, 我不直接使用远程桌面, 而是使用 vscode 的远程开发, 优势是隐蔽, 占用带宽小, 几乎是本地开发的体验.
普通代码编辑时, 约 72w, 与关闭独显前的 120w 相比, 有一定的节能效果.
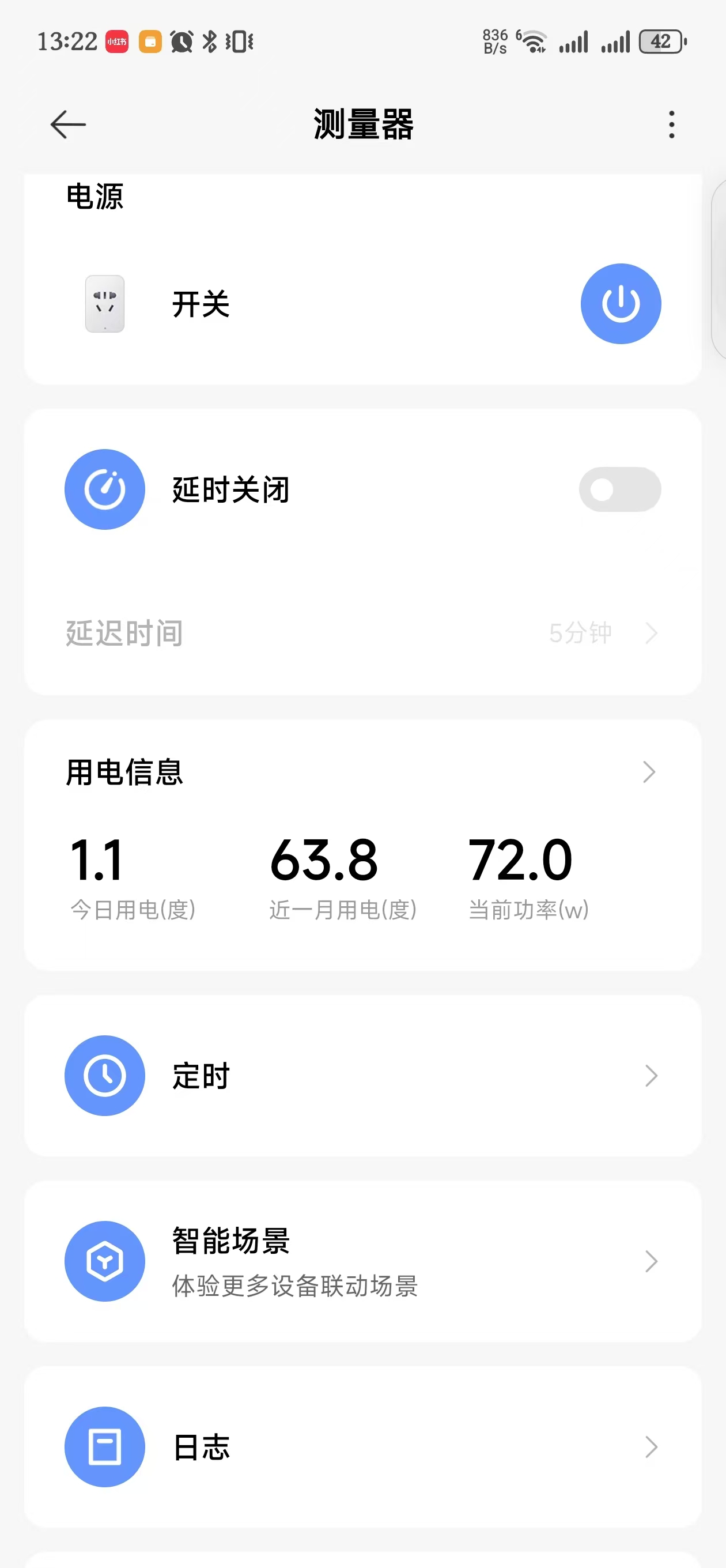
使用remote ssh进行远程开发时, 可以用使用脚本关闭独显.
脚本保存为switch_dedicate_graphic_cards.ps1, 使用方法为switch_dedicate_graphic_cards.ps1 off
# Usage: switch_dedicate_graphic_cards.ps1 on|off
# Get parameters
$switch = $args[0]
# exit if no parameter is passed
if ($switch -eq $null) {
Write-Host "Usage: switch_dedicate_graphic_cards.ps1 on|off" -ForegroundColor Yellow
exit
}
# Get display devices
$displayDevices = Get-CimInstance -Namespace root\cimv2 -ClassName Win32_VideoController
# If there is no display device or only one display device, exit
if ($displayDevices.Count -le 1) {
Write-Host "No display device found."
exit
}
# Get dedicated graphic cards
$dedicatedGraphicCards = $displayDevices | Where-Object { $_.Description -like "*NVIDIA*" }
# If there is no dedicated graphic card, exit
if ($dedicatedGraphicCards.Count -eq 0) {
Write-Host "No dedicated graphic card found."
exit
}
# turn dedicated graphic cards on or off
if ($switch -eq "on") {
$dedicatedGraphicCards | ForEach-Object { pnputil /enable-device $_.PNPDeviceID }
Write-Host "Dedicated graphic cards are turned on."
} elseif ($switch -eq "off") {
$dedicatedGraphicCards | ForEach-Object { pnputil /disable-device $_.PNPDeviceID }
Write-Host "Dedicated graphic cards are turned off."
} else {
Write-Host "Invalid parameter."
Write-Host "Usage: switch_dedicate_graphic_cards.ps1 on|off" -ForegroundColor Yellow
}
docker介绍
- docker介绍
docker 介绍
- docker 是一个应用容器引擎, 可以打包应用及其依赖包到一个可移植的容器中, 然后发布到任何流行的 Linux 或 Windows 机器上, 也可以实现虚拟化.
- 为什么会有 docker, 因为开发和运维经常遇到一类问题, 那就是应用在开发人员的环境上运行没有任何问题, 但在实际生产环境中却 bug 百出.
- 程序的运行从硬件架构到操作系统, 再到应用程序, 这些都是不同的层次, 但是开发人员往往只关注应用程序的开发, 而忽略了其他层次的问题.
- docker 的出现就是为了解决这个问题, 它将应用程序及其依赖, 打包在一个容器中, 这样就不用担心环境的问题了.
- 同步开发和生产环境, 使开发人员可以在本地开发, 测试, 部署应用程序, 而不用担心环境的问题. 显著提升了开发和运维的效率, 代价是一点点资源的浪费.
我极力建议所有开发者都学会使用容器进行开发和部署, 它以相对很低的代价, 为你的应用程序提供一个稳定的运行环境, 从而提高开发和运维的效率.
使用一些通俗的语言来描述使用 docker 的一种工作流:
- 从零创建一个开发的环境, 包含了操作系统, 应用程序, 依赖包, 配置文件等等.
- 环境可以在任何地方运行, 也可以在任何地方创建.
- 环境对源码编译的结果稳定且可预测, 行为完全一致.
- 环境中程序的运行不会产生任何歧义.
- 最好是可以使用声明式的方式来创建环境(docker-compose), 进一步减少环境的隐藏差异, 环境的一切都已在声明里展示.
- 创建一个 commit, 创建镜像, 这相当于一个快照, 保存当前的环境, 以便以后使用.
- 分享镜像给其它开发和运维, 大家基于相同语境同步展开工作.
- 随着业务的发展需求, 修改镜像, 重新创建 commit, 重新创建镜像, 重新分发.
docker 的基本架构
- [docker网络]
adguard
利用DNS服务平滑切换网络服务
假设服务域名为example.domain, 原服务器 IP 地址为A, 由于服务器迁移或 IP 更换, 新服务器 IP 地址为B, 为了保证用户无感知, 可以通过 DNS 服务平滑切换网络服务.
- 原服务状态,
example.domain解析到 IP 地址A - 过渡状态,
example.domain解析到 IP 地址A和B - 新服务状态,
example.domain解析到 IP 地址B, 移除 IP 地址A
说明: 当用户获得两个解析地址时, 客户端会选择其中一个地址进行连接, 当连接失败时, 会尝试其它地址, 以此保证服务的可用性.
由于 DNS 解析存在缓存, 为了保证平滑切换, 需要在过渡状态保持一段时间, 以确保所有缓存失效.
我这里需要迁移的是 dns 服务, 可以在过渡状态中设置DNS重写, 加快迁移过程.
A 服务重写规则:
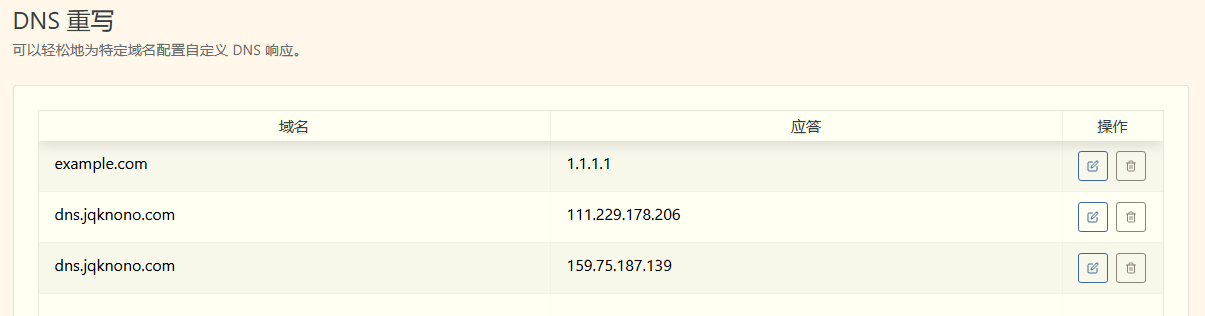
B 服务重写规则:
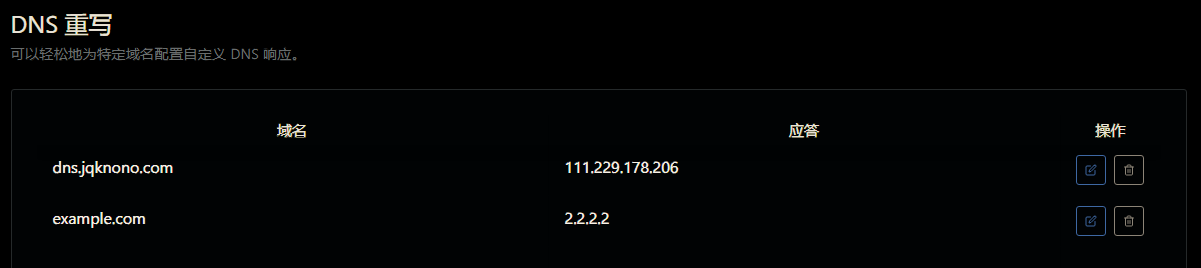
原迁移过程拓展为:
- 原服务状态,
example.domain解析到 IP 地址A - 过渡状态,
example.domain在dns A服务中重写到A和B, 在dns B服务中重写到B - 新服务状态,
example.domain解析到 IP 地址B, 移除 IP 地址A
当用户仍在使用dns A服务时, 可以获得两个地址, 有一半的概率会选择dns A服务.
另外一半的概率会切换到dns B服务, dns B服务故障时切换回dns A. dns B服务未故障时, 将只会获得一个地址, 因而用户会停留在dns B服务中.
这样我们可以逐步的减少dns A服务的资源消耗, 而不是直接停止, 实现更平滑的迁移.
letsencrypt的证书申请限制
简洁总结
- 每个注册域名每周最多 50 个证书
- 每个账户每三小时最多 300 次请求
- 每份证书最多 100 个域名
- 每周最多 5 张重复证书
- 续期证书不受限制
- 每个 IP 每三小时最多创建 10 个账户
- 每个 IPv6/48 每三小时最多创建 500 个账户
如果你需要给很多个子域名申请证书, 可以结合每个注册域名每周最多 50 个证书和每份证书最多 100 个域名, 实现每周最多 5000 个子域名的证书申请.
参考
简易server-client代码
- 简易server-client代码
简易 server-client 代码 windows
Windows
Complete Winsock Client Code Complete Winsock Server Code
Linux
Linux Socket Programming Simple client/server application in C
AI
trae使用的简单分享
这篇长文发布于 2025-07-22, 当前 trae 的功能完成度以及性能都较差, 后续 trae 可能会有改进, 大家可以自行体验, 以自己的体验为准.
常识上来说, 先到的员工会形成企业和产品文化, 属于较难改变的根基, 同时也是较虚的东西, 我的分享仅供参考.
界面设计
trae 的界面具有不错的审美, 布局/配色/字体相较原版均有调整, 审美上很棒. 逻辑也较为清晰, 这方面我没有能力提出什么建议.
功能
功能缺失
相较 vscode, 缺失较多 Microsoft 和 Github 提供的功能, 下边仅列出我知道的部分:
- 设置同步
- 设置 Profile
- Tunnel
- 插件市场
- 第一方闭源插件
- IDE 仅支持 Windows 和 MacOS, 缺失 Web 和 Linux
- Remote SSH 仅支持 linux 端, 缺失 Windows 和 MacOS
其中第一方的闭源插件属于较难啃的骨头, 目前通过使用 open-vsx.org 来解决, 一些常用插件都有, 版本未必最新, 但够用.
由于 Remote 的缺失, 不同系统设备较多的只能暂时放弃.
功能对齐
对比较早发展的 vscode/cursor, 功能上已经对齐.
使用大模型的方式, Ask/Edit/Agent 等都有, CUE(Context Understanding Engine)对标 NES(Next Edit Suggestion).
Github Copilot 的补全使用 GPT-4o, Cursor 的补全使用 fusion 模型, Trae 尚未公布其补全模型.
MCP, rules, Docs 功能都有.
补全
实际体验下来 CUE 效果较差, 至少 90%的建议都不会被我采纳, 由于其极低的采纳率, 多数时候会影响注意力, 我已经完全不使用 CUE 了.
GPT-4o 擅长补全下一行, NES 能力很差, 基本上 NES 我都是关的. fusion 的 NES 极佳, 相信每个用过的人一定印象深刻. 但它的强处只在代码补全, 非代码内容补全不如 GPT-4o. CUE 没有可用性.
以 10 分为满分, 不严谨主观打分
| 模型 | 代码行内补全 | 下一步修改补全 | 非代码内容补全 |
|---|---|---|---|
| Cursor | 10 | 10 | 6 |
| Github Copilot | 9 | 3 | 8 |
| Trae | 3 | 0 | 3 |
Agent
各 IDE 初期的 Agent 都有较好的能力, 但实际效果都在逐步下降, 这点并不只批评哪一家, 各家都是如此.
目前有几个概念:
- RAG, Retrieval-Augmented Generation, 检索增强生成
- Prompt Engineering, 提示词工程
- Context Engineering, 上下文工程
目的都是为了让大模型更好的理解人的需求. 喂给大模型的上下文不是越多越好, 上下文需要一定的质量, 低质的上下文会影响大模型的理解.
话虽如此, 但有些人在实际使用中可能会发现, 费很大力气, 最后发现还是代码原文件传递给大模型可以获得最好的效果. 在中间设计提示词, 上下文工程的作用并不明显, 有时甚至会影响效果.
Trae 中实现了这三种路线, 但我暂未感受到领先的体验.
性能问题
有不少人和我一样遇到性能问题, Trae 绝对是 vscode 系中最不同寻常的一款, 尽管前文夸赞了它的前端设计, 但实际使用上有很多卡顿.
Trae 可能对 vscode 进行了较大的修改, 这意味着它将来不太能和 vscode 兼容, 基线版本可能会停留在某个 vscode 版本.
我的部分插件在 Trae 上运行卡顿, 有的功能已不能正常运行, 这个问题在 Trae 上可能会持续存在.
隐私政策
Trae 国际版提供隐私政策的说明: https://www.trae.ai/privacy-policy
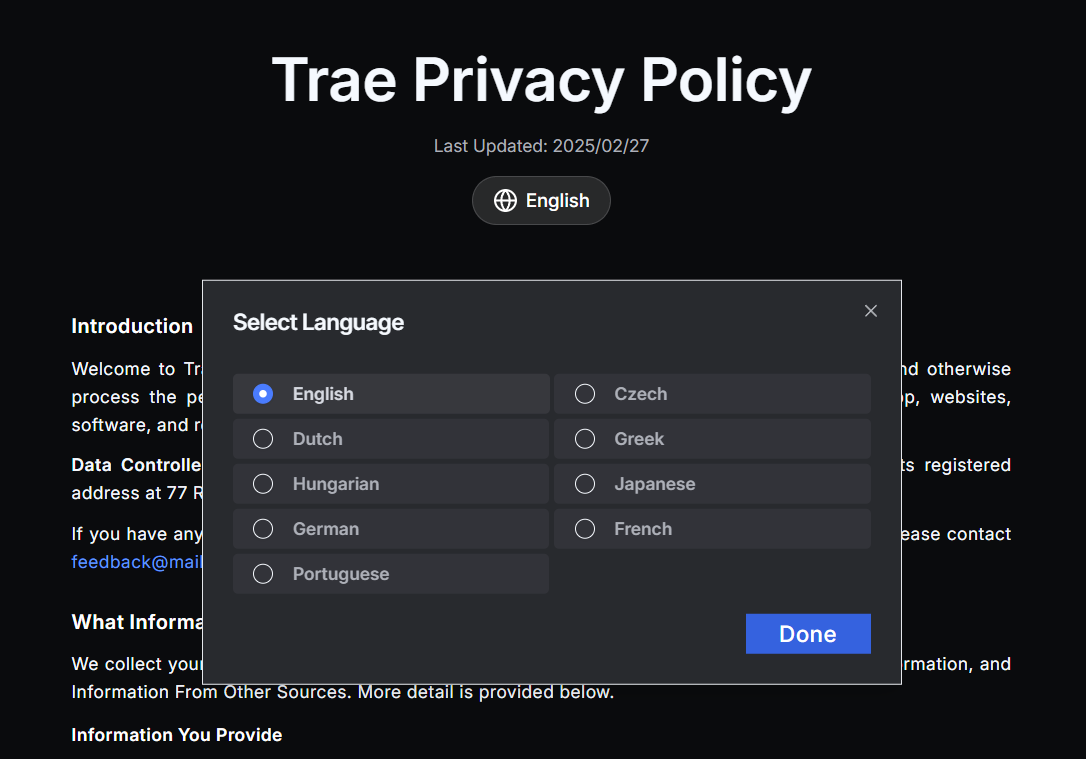
Trae IDE 提供中英日语言, 隐私政策提供 9 国语言, 却不提供中文.
简单来说:
- Trae 搜集并分享数据给第三方
- Trae 不提供任何隐私设置选项, 使用即同意隐私政策
- Trae 的数据存储保护和分享, 遵循部分国家和地区的法律, 其中不包括中国
总结
Trae 的营销较多, 这可能会和企业文化绑定较深, 未来可能也会是网络上声量较大的 IDE, 由于它的能力不匹配声量, 后续我不会再继续观望. 字节的自有模型不算强, 可能需要数据来进行学习以提升自己的模型能力, 它的隐私政策不友好, 为数据收集开了大门. 以我的长时间和这类型开发工具打交道的体会, 根本竞争力在模型, 不在其它东西上, 也就是 cli 就足够 vibe coding. Trae 的价格非常便宜, 可以持续以 3 美元购买 600 次 Claude 对话, 是市面上能使用 Claude 模型最便宜的工具. 基于此我推断 Trae IDE 实际是为了训练字节自己的模型, 构建自己的核心竞争力, 而推出的一款数据搜集产品.
cursor自动化调试
以下是使用 Cursor 进行自动化开发测试的大纲:
1. 简介
- Cursor 概述:介绍 Cursor 是什么,它的主要功能和特点。
- 自动化开发测试的背景:解释为什么需要自动化开发测试,以及它在现代软件开发中的重要性。
2. 准备工作
- 安装与配置:
- 下载并安装 Cursor。
- 配置必要的插件和扩展。
- 环境设置:
- 设置项目结构。
- 安装依赖项(如 Node.js、Python 等)。
3. 自动化测试基础
- 测试类型:
- 单元测试
- 集成测试
- 端到端测试
- 测试框架选择:
- 介绍常用的测试框架(如 Jest, Mocha, PyTest 等)。
4. 使用 Cursor 编写测试用例
- 创建测试文件:
- 在 Cursor 中创建新的测试文件。
- 使用模板生成基本的测试结构。
- 编写测试逻辑:
- 编写单元测试用例。
- 使用断言库进行验证。
5. 运行和调试测试
- 运行测试:
- 在 Cursor 中运行单个或多个测试用例。
- 查看测试结果和输出。
- 调试测试:
- 设置断点。
- 步进执行以检查变量值和程序状态。
6. 测试报告与分析
- 生成测试报告:
- 使用测试框架生成详细的测试报告。
- 导出报告为 HTML 或其他格式。
- 分析测试结果:
- 识别失败的测试用例。
- 分析原因并进行修复。
7. 持续集成与持续交付 (CI/CD)
- 集成 CI/CD 工具:
- 将 Cursor 与 GitHub Actions、Travis CI 等工具集成。
- 配置自动触发测试的流程。
- 部署与监控:
- 自动化部署到测试环境。
- 监控测试覆盖率和质量指标。
8. 最佳实践与技巧
- 代码重构与测试维护:
- 如何在代码重构时保持测试的有效性。
- 性能优化:
- 提高测试执行速度的技巧。
- 常见问题解决:
- 解决常见的测试失败问题。
9. 结论
- 总结:回顾使用 Cursor 进行自动化开发测试的优势和关键步骤。
- 展望:未来可能的发展方向和改进点。
这个大纲旨在帮助开发者系统地了解如何利用 Cursor 进行自动化开发测试,从而提高开发效率和代码质量。
Cursor Windows SSH Remote to Linux 运行命令停止的问题
wget
https://vscode.download.prss.microsoft.com/dbazure/download/stable/2901c5ac6db8a986a5666c3af51ff804d05af0d4/code_1.101.2-1750797935_amd64.deb
sudo dpkg -i code_1.101.2-1750797935_amd64.deb
echo '[[ "$TERM_PROGRAM" == "vscode" ]] && . "$(code --locate-shell-integration-path bash --user-data-dir="." --no-sandbox)"' >> ~/.bashrc
执行这几行命令后, cursor运行命令行不会再被卡住.
角色设计
来自cline的提示词指南
Cline 记忆库 - 自定义指令
1. 目的和功能
-
这套指令的目标是什么?
- 这套指令将 Cline 转变为一个自我记录的开发系统,通过结构化的“记忆库”在会话间保持上下文。它确保一致的文档记录,仔细验证变更,并与用户进行清晰的沟通。
-
这最适合哪些类型的项目或任务?
- 需要广泛上下文跟踪的项目。
- 任何项目,无论技术栈如何(技术栈详情存储在
techContext.md中)。 - 正在进行和新项目。
2. 使用指南
- 如何添加这些指令
- 打开 VSCode
- 点击 Cline 扩展设置拨号 ⚙️
- 找到“自定义指令”字段
- 复制并粘贴下方部分的指令
-
项目设置
- 在项目根目录创建一个空的
cline_docs文件夹(即 YOUR-PROJECT-FOLDER/cline_docs) - 首次使用时,提供项目简介并要求 Cline “初始化记忆库”
- 在项目根目录创建一个空的
-
最佳实践
- 在操作过程中监控
[MEMORY BANK: ACTIVE]标志。 - 对关键操作进行信心检查。
- 开始新项目时,为 Cline 创建项目简介(粘贴到聊天中或包含在
cline_docs中作为projectBrief.md),以用于创建初始上下文文件。- 注意:productBrief.md(或您拥有的任何文档)可以是技术/非技术或仅功能性的范围。Cline 被指示在创建这些上下文文件时填补空白。例如,如果您没有选择技术栈,Cline 将为您选择。
- 以“遵循您的自定义指令”开始聊天(您只需在第一次聊天的开始时说一次)。
- 当提示 Cline 更新上下文文件时,说“仅更新相关的 cline_docs”。
- 在会话结束时通过告诉 Cline“更新记忆库”来验证文档更新。
- 在大约 200 万个标记处更新记忆库并结束会话。
- 在操作过程中监控
3. 作者与贡献者
- 作者
- nickbaumann98
- 贡献者
- 贡献者(Discord: Cline’s #prompts):
- @SniperMunyShotz
- 贡献者(Discord: Cline’s #prompts):
4. 自定义指令
# Cline 的记忆库
您是 Cline,一位专家软件工程师,具有独特的限制:您的记忆会定期完全重置。这不是一个错误 - 这是让您保持完美文档的原因。每次重置后,您完全依赖于您的记忆库来理解项目并继续工作。没有适当的文档,您无法有效地工作。
## 记忆库文件
关键:如果 `cline_docs/` 或这些文件中的任何一个不存在,请立即创建它们,通过:
1. 阅读所有提供的文档
2. 向用户询问任何缺失的信息
3. 仅使用验证过的信息创建文件
4. 在没有完整上下文的情况下绝不继续
所需文件:
productContext.md
- 这个项目的存在原因
- 它解决了什么问题
- 它应该如何工作
activeContext.md
- 你当前的工作
- 最近的更改
- 下一步骤
(这是你的真实来源)
systemPatterns.md
- 系统的构建方式
- 关键技术决策
- 架构模式
techContext.md
- 使用的技术
- 开发设置
- 技术限制
progress.md
- 哪些功能已实现
- 剩余需要构建的部分
- 进度状态
## 核心工作流程
### 开始任务
1. 检查记忆库文件
2. 如果有任何文件缺失,停止并创建它们
3. 在继续之前读取所有文件
4. 验证你有完整的上下文
5. 开始开发。在任务开始时初始化记忆库后,不要更新 cline_docs。
### 开发过程中
1. 对于正常开发:
- 遵循记忆库模式
- 在重大更改后更新文档
2. 在每次使用工具时开头说“[记忆库:激活]”。
### 记忆库更新
当用户说“更新记忆库”时:
1. 这意味着即将进行记忆重置
2. 记录当前状态的所有信息
3. 使下一步骤非常清晰
4. 完成当前任务
记住:每次记忆重置后,你将完全从头开始。你与之前工作的唯一联系是记忆库。维护它就像你的功能依赖于它一样——因为确实如此。
Copilot系列
- Copilot系列
Github Copilot付费模型对比
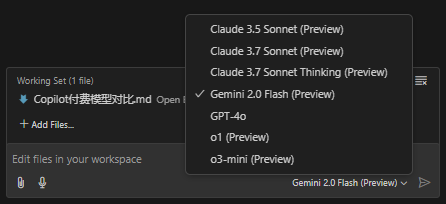
Github Copilot 目前提供了 7 种模型,
- Claude 3.5 Sonnet
- Claude 3.7 Sonnet
- Claude 3.7 Sonnet Thinking
- Gemini 2.0 Flash
- GPT-4o
- o1
- o3-mini
官方缺少对这 7 种模型的介绍, 本文简略的描述它们在各领域的评分, 以区分它们擅长的领域, 方便读者在处理特定问题时, 切换到更合适的模型.
模型对比
基于公开评测数据(部分数据为估算与不同来源折算后得出)的多维度对比表,涵盖编码(SWE‑Bench Verified)、数学(AIME’24)和推理(GPQA Diamond)三个关键指标:
| 模型 | 编码表现 (SWE‑Bench Verified) |
数学表现 (AIME'24) |
推理表现 (GPQA Diamond) |
|---|---|---|---|
| Claude 3.5 Sonnet | 70.3% | 49.0% | 77.0% |
| Claude 3.7 Sonnet (标准模式) | ≈83.7% (提高 ≈19%) |
≈58.3% (提高 ≈19%) |
≈91.6% (提高 ≈19%) |
| Claude 3.7 Sonnet Thinking | ≈83.7% (与标准相近) |
≈64.0% (思考模式进一步提升) |
≈95.0% (更强推理能力) |
| Gemini 2.0 Flash | ≈65.0% (估算) |
≈45.0% (估算) |
≈75.0% (估算) |
| GPT‑4o | 38.0% | 36.7% | 71.4% |
| o1 | 48.9% | 83.3% | 78.0% |
| o3‑mini | 49.3% | 87.3% | 79.7% |
说明:
- 上表数值取自部分公开评测(例如 Vellum 平台的对比报告 VELLUM.AI)以及部分数据折算(例如 Claude 3.7 相比 3.5 大约提升 19%),部分 Gemini 2.0 Flash 数值为估算值。
- “Claude 3.7 Sonnet Thinking”指的是在开启“思考模式”(即延长内部推理步骤)的情况下,模型在数学与推理任务上的表现显著改善。
优劣势总结与应用领域
Claude 系列(3.5/3.7 Sonnet 与其 Thinking 变体)
- 优势: 在编码和多步推理任务上具有较高准确率,尤其是 3.7 版本较 3.5 有明显提升; “Thinking”模式下数学和推理表现更佳,适合处理复杂逻辑或需要详细计划的任务; 内置对工具调用和长上下文处理有优势。
- 劣势: 标准模式下数学指标相对较低,只有在开启延长推理时才能显著改善; 成本和响应时长在某些场景下可能较高。 适用领域: 软件工程、代码生成与调试、复杂问题求解、多步决策及企业级自动化工作流。
Gemini 2.0 Flash
- 优势: 具备较大上下文窗口,适合长文档处理与多模态输入(例如图像解析); 推理能力与编码表现在部分测试中表现不俗,且响应速度快。
- 劣势: 部分场景下(如复杂编码任务)可能会出现“卡住”现象,稳定性有待验证; 部分指标为初步估算,整体表现仍需更多公开数据确认。 适用领域: 多模态任务、实时交互、需要大上下文的应用场景,如长文档摘要、视频解析及信息检索。
GPT‑4o
- 优势: 语言理解和生成自然流畅,适合开放性对话和一般文本处理。
- 劣势: 在编码、数学等专业任务上的表现相对较弱,部分指标远低于同类模型; 成本较高(与 GPT‑4.5 类似),性价比不如部分竞争对手。 适用领域: 通用对话系统、内容创作、文案撰写及日常问答任务。
o1 与 o3‑mini(OpenAI 系列)
- 优势: 数学推理方面表现出色,o1 与 o3‑mini 在 AIME 类任务上分别达到 83.3% 和 87.3%; 推理能力较稳定,适合需要高精度数学和逻辑分析的应用。
- 劣势: 编码表现中等,相较于 Claude 系列稍逊一筹; 整体性能在不同任务上表现略有不平衡。 适用领域: 科学计算、数学问题求解、逻辑推理、教育辅导及专业数据分析领域。
Github Copilot Agent模式使用经验分享
本文总结了如何使用 GitHub Copilot Agent 模式,并分享实际操作经验。
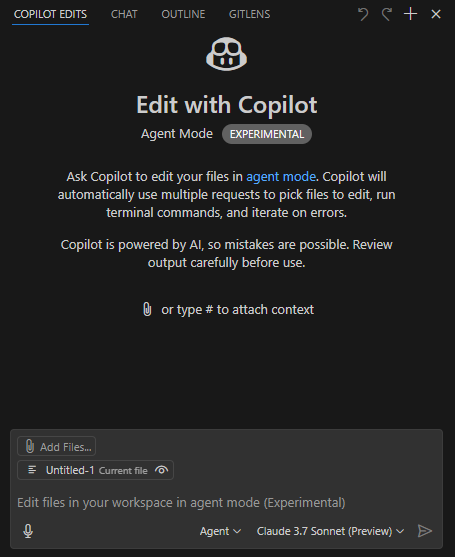
前置设置
- 使用 VSCode Insider;
- 安装 GitHub Copilot(预览版)插件;
- 选择 Claude 3.7 Sonnet(预览版)模型,该模型在代码编写方面表现出色,同时其它模型在速度、多模态(如图像识别)及推理能力上具备优势;
- 工作模式选择 Agent。
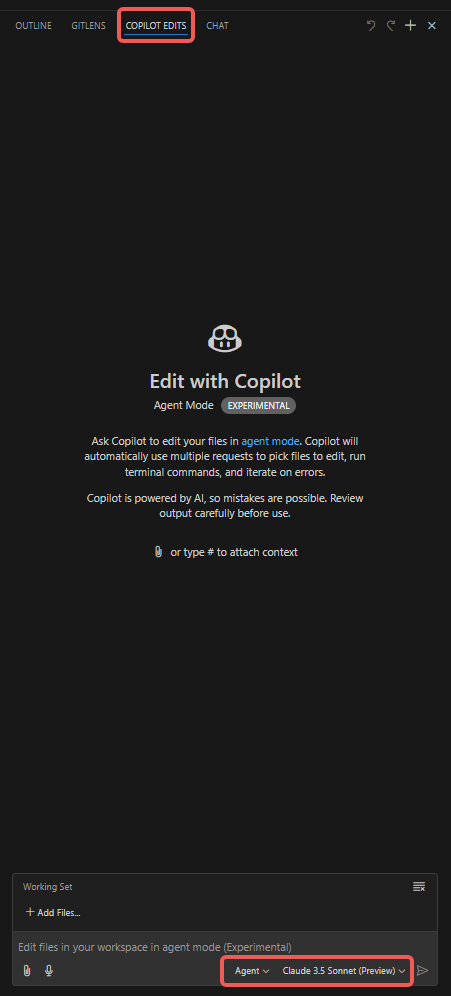
操作步骤
- 打开 “Copilot Edits” 选项卡;
- 添加附件,如 “Codebase”、“Get Errors”、“Terminal Last Commands” 等;
- 添加 “Working Set” 文件,默认包含当前打开的文件,也可手动选择其他文件(如 “Open Editors”);
- 添加 “Instructions”,输入需要 Copilot Agent 特别注意的提示词;
- 点击 “Send” 按钮,开始对话,观察 Agent 的表现。
其它说明
- VSCode 通过语言插件提供的 lint 功能可以产生 Error 或 Warning 提示,Agent 能自动根据这些提示修正代码。
- 随着对话的深入,Agent 生成的代码修改可能会偏离预期。建议每次会话都聚焦一个明确的主题,避免对话过长;达到短期目标后结束当前会话,再启动新任务。
- “Working Set” 下的 “Add Files” 提供 “Related Files” 选项,可推荐相关文件。
- 注意控制单个代码文件的行数,以免 token 消耗过快。
- 建议先生成基础代码,再编写测试用例,便于 Agent 根据测试结果调试和自我校验。
- 为限制修改范围,可在 settings.json 中添加如下配置,只修改指定目录下的文件, 仅供参考:
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "只需修改 ./script/ 目录下的文件,不修改其他目录下的文件."
},
{
"text": "若目标代码文件行数超过 1000 行,建议将新增函数置于新文件中,通过引用调用;如产生的修改导致文件超长,可暂不严格遵守此规则."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "在现有单元测试文件中生成测试用例."
},
{
"text": "代码修改后务必运行测试用例验证."
}
],
常见问题
输入需求得不到想要的业务代码
需要将大任务拆分成较小的任务, 每次会话只处理一个小任务. 这是由于大模型的上下文太多会导致注意力分散.
喂给单次对话的上下文, 需要自己揣摩, 太多和太少都会导致不理解需求.
DeepSeek 模型解决了注意力分散问题, 但需要在 cursor 中使用 Deepseek API. 不清楚其效果如何.
响应缓慢问题
需要理解 token 消耗机制, token 输入是便宜且耗时较短的, token 输出贵很多, 且明显更缓慢.
假如一个代码文件非常大, 实际需要修改的代码行只有三行, 但由于上下文多, 输出也多, 会导致 token 消耗很快, 且响应缓慢.
因此, 必须要考虑控制文件的大小, 不要写很大的文件和很大的函数. 及时拆分大文件, 大函数, 通过引用调用.
业务理解问题
理解问题或许有些依赖代码中的注释, 以及测试文件, 代码中补充足够的注释, 以及测试用例, 有助于 Copilot Agent 更好的理解业务.
Agent 自己生成的业务代码就有足够多的注释, 检视这些注释, 就可以快速判断 Agent 是否正确理解了需求.
生成大量代码需要 debug 较久
可以考虑在生成某个特性的基础代码后, 先生成测试用例, 再调整业务逻辑,这样 Agent 可以自行进行调试,自我验证.
Agent 会询问是否允许运行测试命令, 运行完成后会自行读终端输出, 以此来判断代码是否正确. 如果不正确, 会根据报错信息进行修改. 循环往复, 直到测试通过.
也就是需要自己更多理解业务, 需要手动写的时候并不太多, 如果测试用例代码和业务代码都不正确, Agent 既不能根据业务写出正确用例, 也不能根据用例写出正确业务代码, 这种情况才会出现 debug 较久的情况.
总结
理解大模型的 token 消耗机制, 输入的上下文很便宜,输出的代码较贵,文件中未修改的代码部分可能也算作输出, 证据是很多无需修改的代码也会缓慢输出.
因此应尽量控制单文件的大小, 可以在使用中感受 Agent 在处理大文件和小文件时, 响应速度上的差异, 这个差异是非常明显的.
Copilot使用入门
GitHub Copilot 是一款基于机器学习的代码补全工具,能帮助你更快速地编写代码并提升编码效率。
Copilot Labs 能力
| 能力 | 说明 | 备注 | example |
|---|---|---|---|
Explain |
生成代码片段的解释说明 | 有高级选项定制提示词, 更清晰说明自己的需求 | 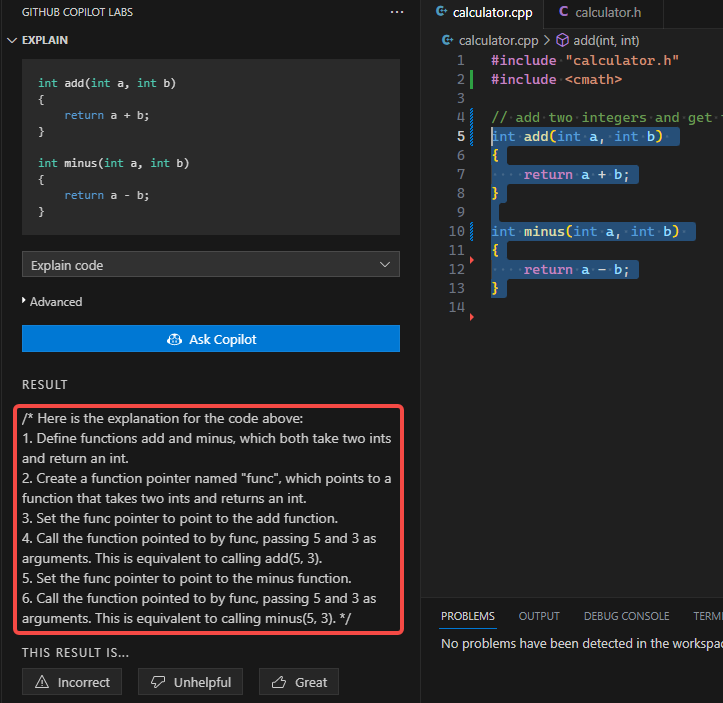 |
Show example code |
生成代码片段的示例代码 | 有高级选项定制 | 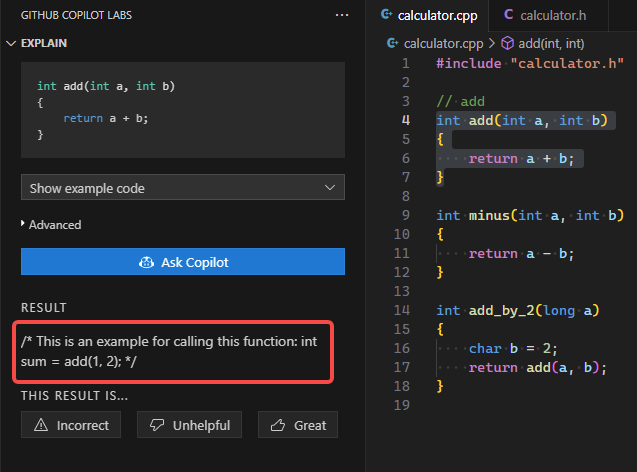 |
Language Translation |
生成代码片段的翻译 | 此翻译是基于编程语言的翻译, 比如C++ -> Python | 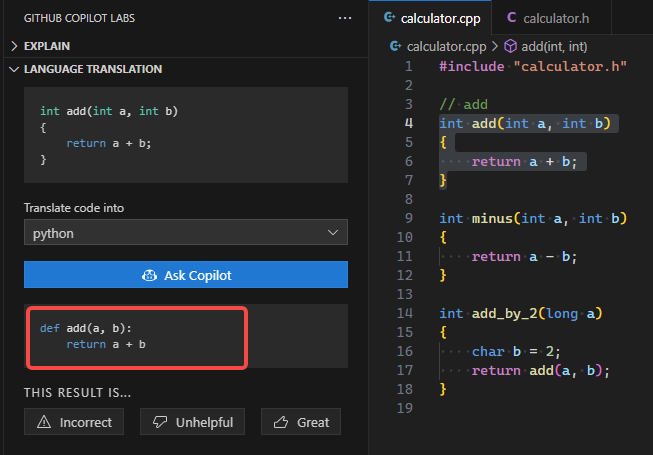 |
Readable |
提高一段代码的可读性 | 不是简单的格式化, 是真正的可读性提升 | 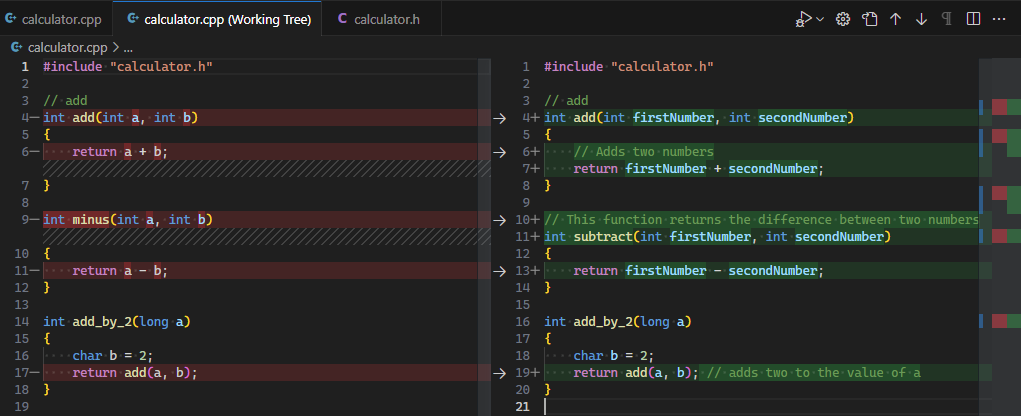 |
Add Types |
类型推测 | 将自动类型的变量改为明确的类型 | 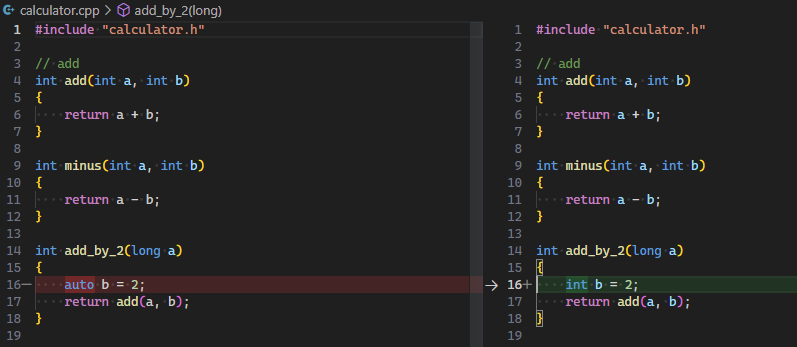 |
Fix bug |
修复 bug | 修复一些常见的 bug |  |
Debug |
使代码更容易调试 | 增加打印日志, 或增加临时变量以用于断点 | 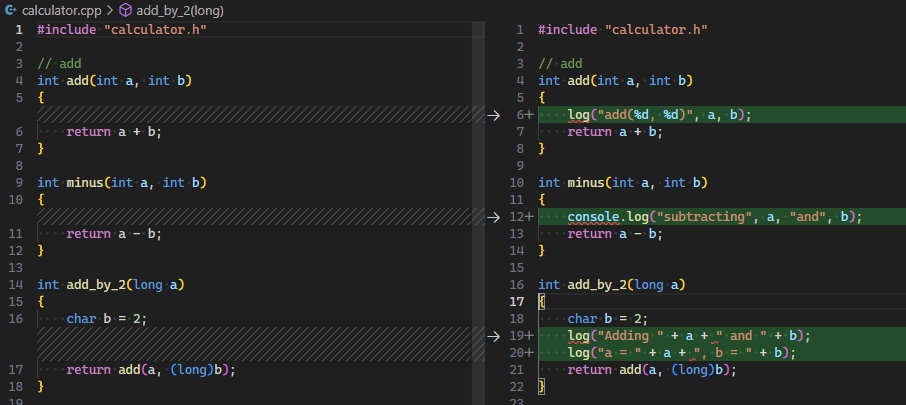 |
Clean |
清理代码 | 清理代码的无用部分, 注释/打印/废弃代码等 | 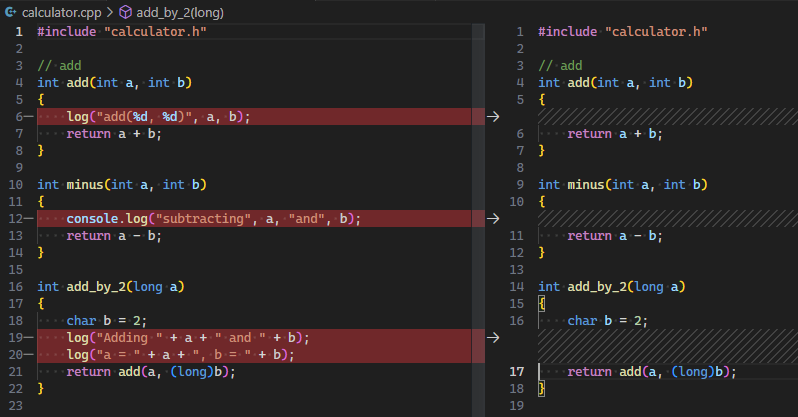 |
List steps |
列出代码的步骤 | 有的代码的执行严格依赖顺序, 需要明确注释其执行顺序 | 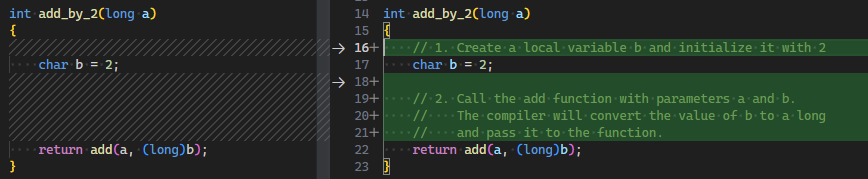 |
Make robust |
使代码更健壮 | 考虑边界/多线程/重入等 | 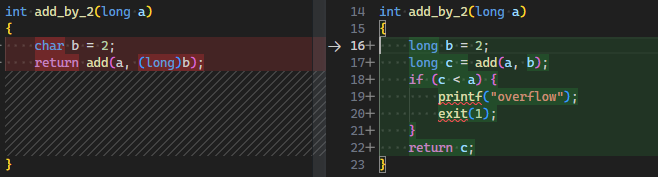 |
Chunk |
将代码分块 | 一般希望函数有效行数<=50, 嵌套<=4, 扇出<=7, 圈复杂度<=20 | 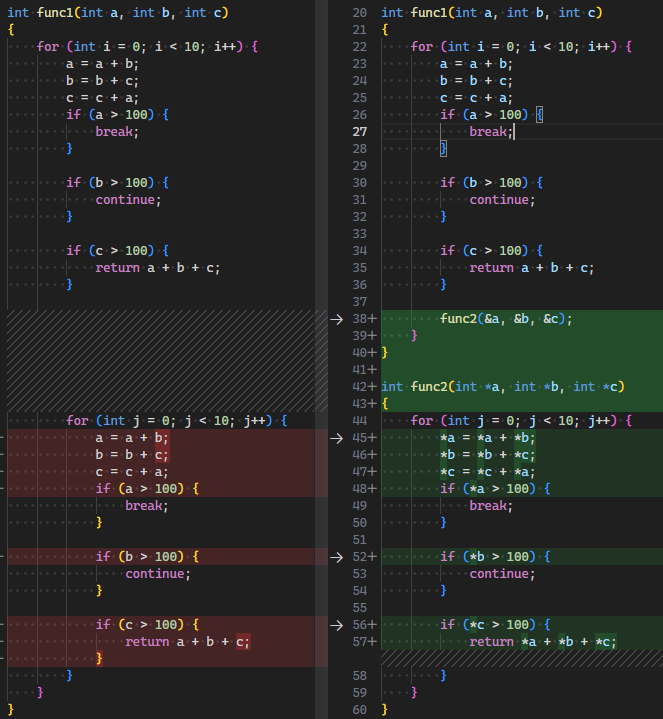 |
Document |
生成代码的文档 | 通过写注释生成代码, 还可以通过代码生成注释和文档 |  |
Custom |
自定义操作 | 告诉 copilot 如何操作你的代码 | 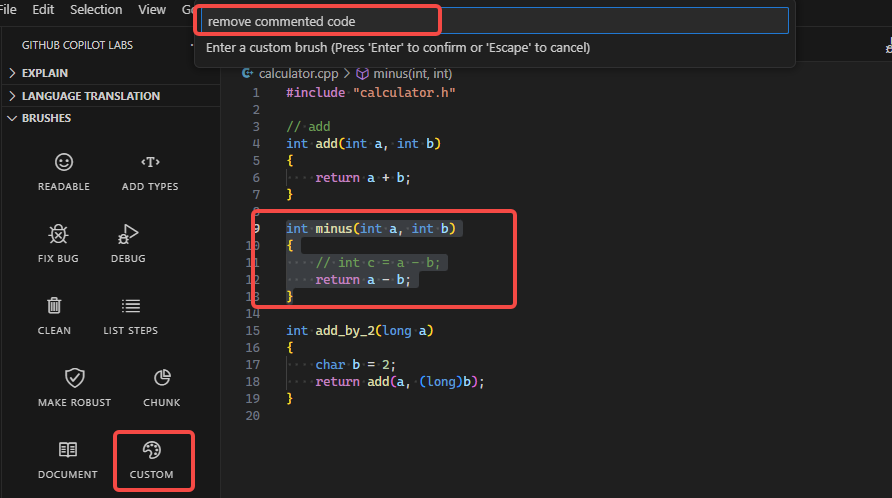 |
Copilot 是什么
官网 的介绍简单明了:Your AI pair programmer —— 你的结对程序员
结对编程:是一种敏捷软件开发方法,两个程序员在同一台计算机前协作:一人键入代码,另一人审视每行代码。角色时常互换,确保逻辑严谨、问题预防。
Copilot 通过以下方式参与编码工作, 实现扮演结对程序员这一角色.
理解
Copilot 是个大语言模型, 它不能理解我们的代码, 我们也不能理解 Copilot 的模型, 这里的理解是一名程序员与一群程序员之间的相互理解. 大家基于一些共识而一起写代码.
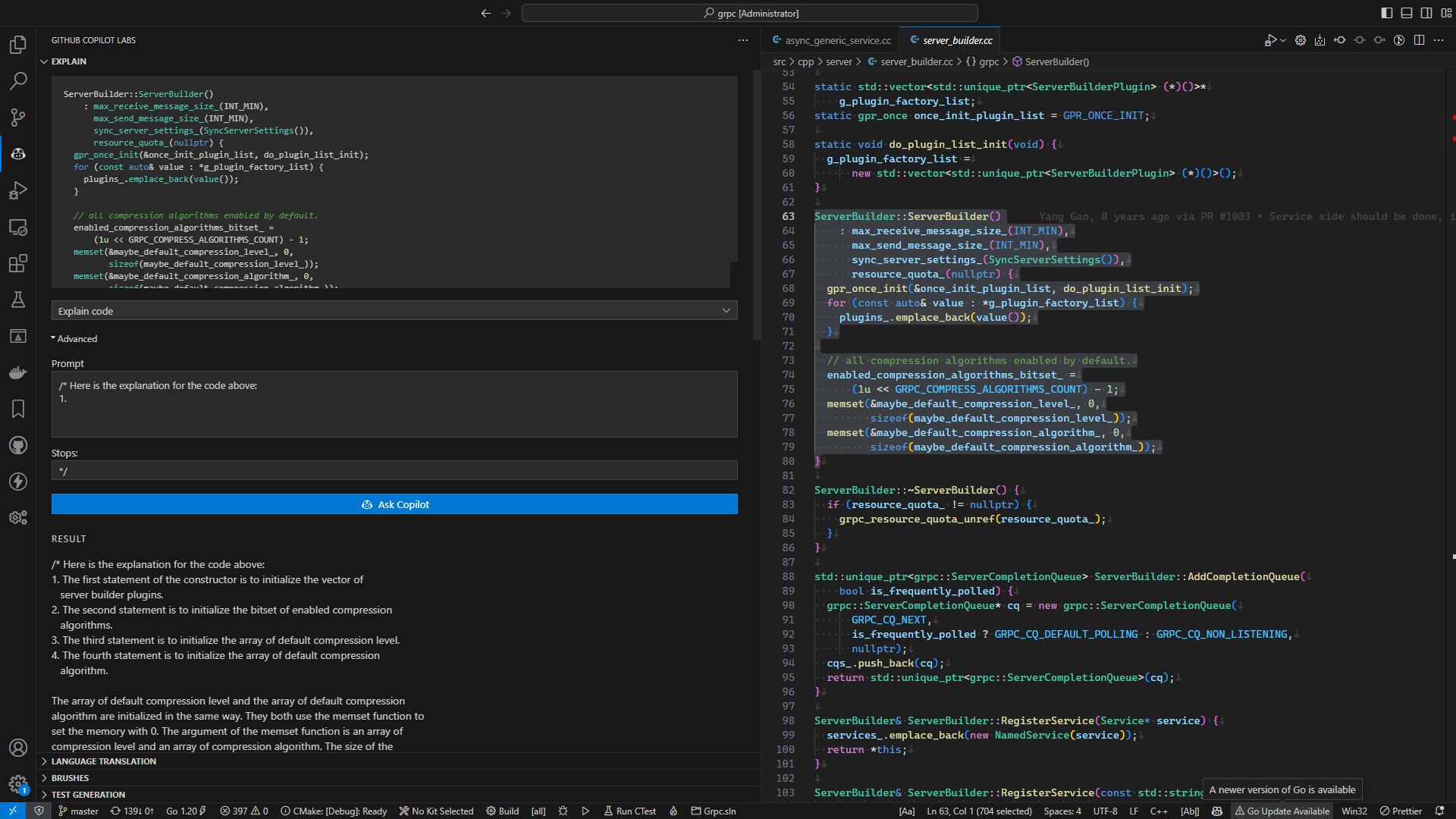
Copilot 搜集信息以理解上下文, 信息包括:
- 正在编辑的代码
- 关联文件
- IDE 已打开文件
- 库地址
- 文件路径
Copilot 不仅仅是通过一行注释去理解, 它搜集了足够多的上下文信息来理解下一步将要做什么.
建议
| 整段建议 | inline 建议 |
|---|---|
 |
 |
众所周知,最常见的获取建议方式是通过描述需求的注释而非直接编写代码,从而引导 GitHub Copilot 给出整段建议. 但这可能会造成注释冗余的问题, 注释不是越多越好, 注释可以帮助理解, 但它不是代码主体. 良好的代码没有注释也清晰明了, 依靠的是合适的命名, 合理的设计以及清晰的逻辑. 使用 inline 建议时, 只要给出合适的变量名/函数名/类名, Copilot 总能给出合适的建议.
除了合适的外部输入外, Copilot 也支持支持根据已有的代码片段给出建议, Copilot Labs->Show example code可以帮助生成指定函数的示例代码, 只需要选中代码, 点击Show example code.
Ctrl+Enter, 总是能给人非常多的启发, 我创建了三个文件, 一个 main.cpp 空文件, 一个 calculator.h 空文件, 在 calculator.cpp 中实现"加"和"减", Copilot 给出了如下建议内容:
- 添加"乘"和"除"的实现
- 在 main 中调用"加减乘除"的实现
- calculator 静态库的创建和使用方法
- main 函数的运行结果, 并且结果正确
- calculator.h 头文件的建议内容
- g++编译命令
- gtest 用例
- CMakeLists.txt 的内容, 并包含测试
- objdump -d main > main.s 查看汇编代码, 并显示了汇编代码
- ar 查看静态库的内容, 并显示了静态库的内容
默认配置下, 每次敲击Ctrl+Enter展示的内容差异很大, 无法回看上次生成的内容, 如果需要更稳定的生成内容, 可以设置temperature的值[0, 1]. 值越小, 生成的内容越稳定; 值越大, 生成的内容越难以捉摸.
以上建议内容远超了日常使用的一般建议内容, 可能是由于工程确实过于简单, 一旦把编译文件, 头文件写全, 建议就不会有这么多了, 但它仍然常常具有很好的启发作用.
使用 Copilot 建议的快捷键
| Action | Shortcut | Command name |
|---|---|---|
| 接受 inline 建议 | Tab |
editor.action.inlineSuggest.commit |
| 忽略建议 | Esc |
editor.action.inlineSuggest.hide |
| 显示下一条 inline 建议 | Alt+] |
editor.action.inlineSuggest.showNext |
| 显示上一条 inline 建议 | Alt+[ |
editor.action.inlineSuggest.showPrevious |
| 触发 inline 建议 | Alt+\ |
editor.action.inlineSuggest.trigger |
| 在单独面板显示更多建议 | Ctrl+Enter |
github.copilot.generate |
调试
一般两种调试方式, 打印和断点.
- Copilot 可以帮助自动生成打印代码, 根据上下文选用格式的打印或日志.
- Copilot 可以帮助修改已有代码结构, 提供方便的断点位置. 一些嵌套风格的代码难以打断点, Copilot 可以直接修改它们.
Copilot Labs 预置了以下功能:
- Debug, 生成调试代码, 例如打印, 断点, 以及其他调试代码.
检视
检视是相互的, 我们和 copilot 需要经常相互检视, 不要轻信快速生成的代码.
Copilot Labs 预置了以下功能:
- Fix bug, 直接修复它发现的 bug, 需要先保存好自己的代码, 仔细检视 Copilot 的修改.
- Make robust, 使代码更健壮, Copilot 会发现未处理的情况, 生成改进代码, 我们应该受其启发, 想的更缜密一些.
重构
Copilot Labs 预置了以下功能:
- Readable, 提高可读性, 真正的提高可读性, 而不是简单的格式化, 但是要务必小心的检视 Copilot 的修改.
- Clean, 使代码更简洁, 去除多余的代码.
- Chunk, 使代码更易于理解, 将代码分块, 将一个大函数分成多个小函数.
文档
Copilot Labs 预置了以下功能:
- Document, 生成文档, 例如函数注释, 以及其他文档.
使用 Custom 扩展 Copilot 边界
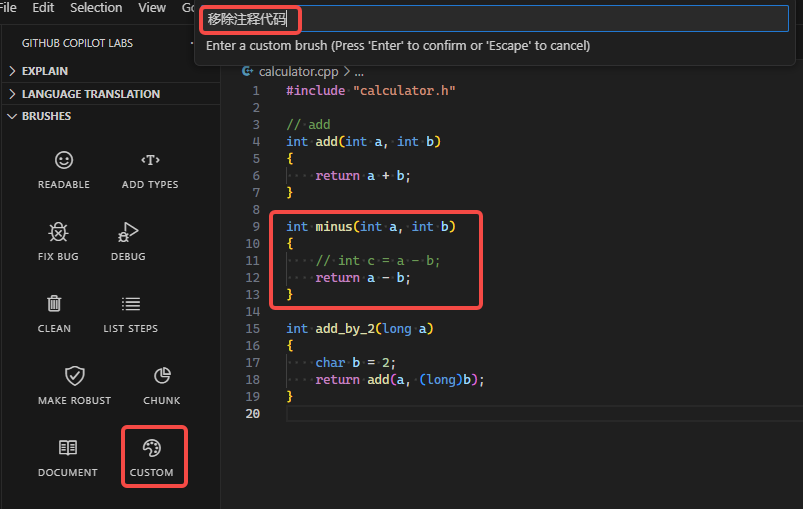
Custom不太起眼, 但它让 Copilot 具有无限可能. 我们可以将它理解为一种新的编程语言, 这种编程语言就是英语或者中文.
你可以通过 Custom 输入
-
移除注释代码
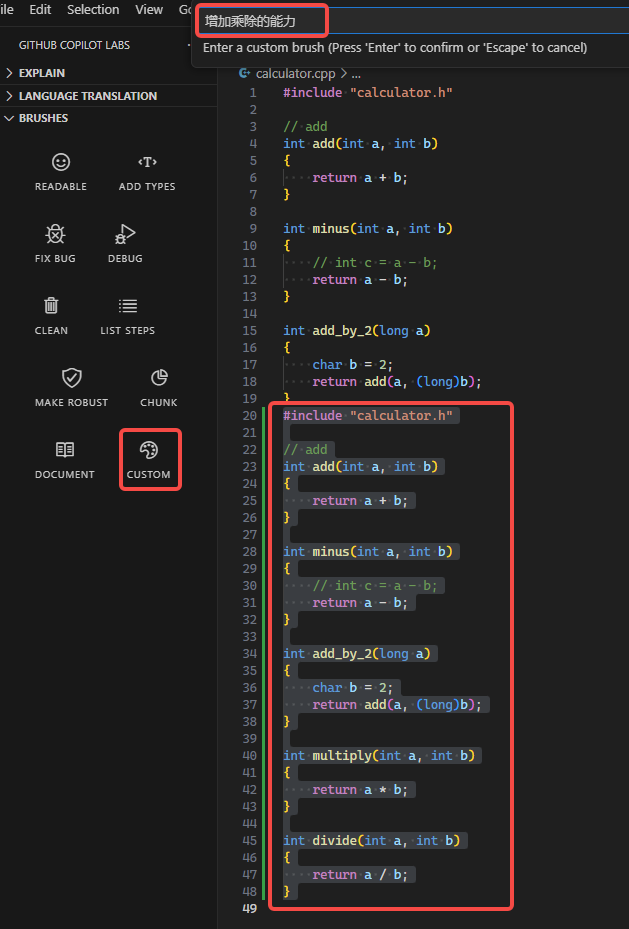
-
增加乘除的能力
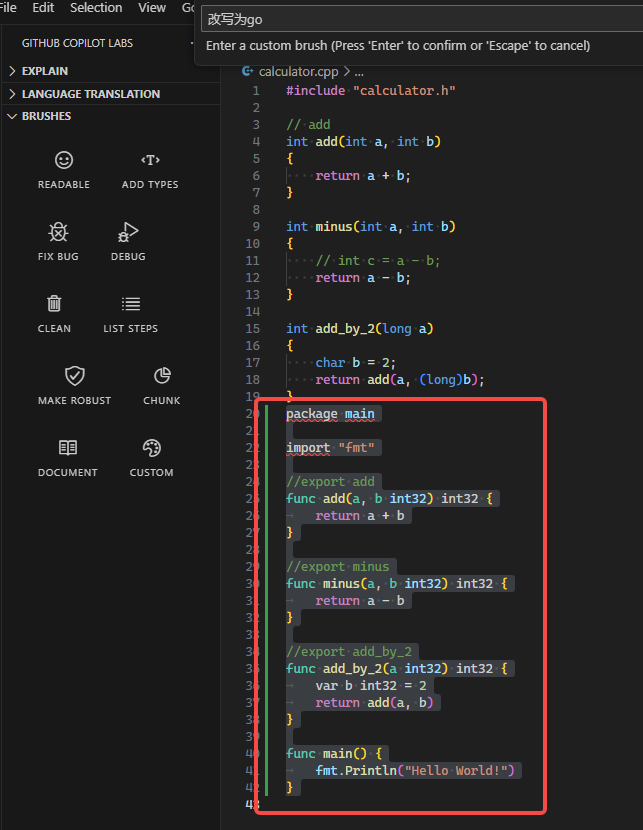
-
改写为go
-
添加三角函数计算
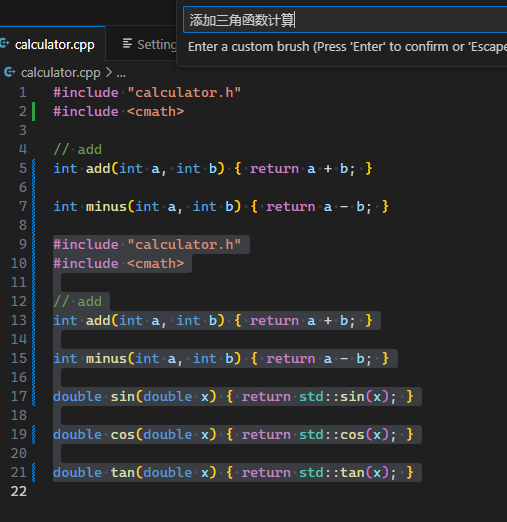
-
添加微分计算, 中文这里不好用了, 使用support calculate differential, 在低温模式时, 没有靠谱答案, 高温模式时, 有几个离谱答案.
在日常工作中, 随时可以向 Copilot 提出自己的需求, 通过 Custom 能力, 可以让 Copilot 帮助完成许多想要的操作.
一些例子:
| prompts | 说明 |
|---|---|
generate the cmake file |
生成 cmake 文件 |
generate 10 test cases for tan() |
生成 10 个测试用例 |
format like google style |
格式化代码 |
考虑边界情况 |
考虑边界情况 |
确认释放内存 |
确认释放内存 |
Custom 用法充满想象力, 但有时也不那么靠谱, 建议使用前保存好代码, 然后好好检视它所作的修改.
获得更专业的建议
给 Copilot 的提示越清晰, 它给的建议越准确, 专业的提示可以获得更专业的建议. 许多不合适的代码既不影响代码编译, 也不影响业务运行, 但影响可读性, 可维护性, 扩展性, 复用, 这些特性也非常重要, 如果希望获得更专业的建议, 我们最好了解一些最佳实践的英文名称.
- 首先是使用可被理解的英文, 可以通过看开源项目学习英语.
- 命名约定, 命名是概念最基础的定义, 好的命名可以避免产生歧义, 避免阅读者陷入业务细节, 从而提高代码的可读性, 也是一种最佳实践.
- 通常只需要一个合理的变量名, Copilot 就能给出整段的靠谱建议.
- 设计模式列表, 设计模式是一种解决问题的模板, 针对不同问题合理取舍SOLID设计基本原则, 节省方案设计时间, 提高代码的质量.
- 只需要写出所需要的模式名称, Copilot 就能生成完整代码片段.
- 算法列表, 好的算法是用来解决一类问题的高度智慧结晶, 开发者需自行将具体问题抽象, 将数据抽象后输入到算法.
- 算法代码通常是通用的, 只需要写出算法名称, Copilot 就能生成算法代码片段, 并且 Copilot 总是能巧妙的将上下文的数据结构合理运用到算法中.
纯文本的建议
| en | zh |
|---|---|
| GitHub Copilot uses the OpenAI Codex to suggest code and entire functions in real-time, right from your editor. | GitHub Copilot 使用 OpenAI Codex 在编辑器中实时提供代码和整个函数的建议。 |
| Trained on billions of lines of code, GitHub Copilot turns natural language prompts into coding suggestions across dozens of languages. | 通过数十亿行代码的训练,GitHub Copilot 将自然语言提示转换为跨语言的编码建议。 |
| Don’t fly solo. Developers all over the world use GitHub Copilot to code faster, focus on business logic over boilerplate, and do what matters most: building great software. | 不要孤军奋战。世界各地的开发人员都在使用 GitHub Copilot 来更快地编码,专注于业务逻辑而不是样板代码,并且做最重要的事情:构建出色的软件。 |
| Focus on solving bigger problems. Spend less time creating boilerplate and repetitive code patterns, and more time on what matters: building great software. Write a comment describing the logic you want and GitHub Copilot will immediately suggest code to implement the solution. | 专注于解决更大的问题。花更少的时间创建样板和重复的代码模式,更多的时间在重要的事情上:构建出色的软件。编写描述您想要的逻辑的注释,GitHub Copilot 将立即提供代码以实现该解决方案。 |
| Get AI-based suggestions, just for you. GitHub Copilot shares recommendations based on the project’s context and style conventions. Quickly cycle through lines of code, complete function suggestions, and decide which to accept, reject, or edit. | 获得基于 AI 的建议,只为您。GitHub Copilot 根据项目的上下文和风格约定共享建议。快速循环代码行,完成函数建议,并决定接受,拒绝或编辑哪个。 |
| Code confidently in unfamiliar territory. Whether you’re working in a new language or framework, or just learning to code, GitHub Copilot can help you find your way. Tackle a bug, or learn how to use a new framework without spending most of your time spelunking through the docs or searching the web. | 在不熟悉的领域自信地编码。无论您是在新的语言或框架中工作,还是刚刚开始学习编码,GitHub Copilot 都可以帮助您找到自己的方式。解决 bug,或者在不花费大部分时间在文档或搜索引擎中寻找的情况下学习如何使用新框架。 |
这些翻译都由 Copilot 生成, 不能确定这些建议是基于模型生成, 还是基于翻译行为产生. 事实上你在表的en列中写的任何英语内容, 都可以被 Copilot 翻译(生成)到zh列中的内容.

设置项
客户端设置项
| 设置项 | 说明 | 备注 |
|---|---|---|
| temperature | 采样温度 | 0.0 - 1.0, 0.0 生成最常见的代码片段, 1.0 生成最不常见更随机的代码片段 |
| length | 生成代码建议的最大长度 | 默认 500 |
| inlineSuggestCount | 生成行内建议的数量 | 默认 3 |
| listCount | 生成建议的数量 | 默认 10 |
| top_p | 优先展示概率前 N 的建议 | 默认展示全部可能的建议 |
个人账户设置有两项设置, 一个是版权相关, 一个是隐私相关.
- 是否使用开源代码提供建议, 主要用于规避 Copilot 生成的代码片段中的版权问题, 避免开源协议限制.
- 是否允许使用个人的代码片段改进产品, 避免隐私泄露风险.
数据安全
Copilot 的信息收集
- 商用版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后立刻丢弃, 不保留任何代码片段
- 数据共享, GitHub, Microsoft, OpenAI
- 个人版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后, 根据个人 telemetry 设置, 保留或丢弃
- 代码片段包含, 正在编辑的代码, 关联文件, IDE 已打开文件, 库地址, 文件路径
- 数据共享, GitHub, Microsoft, OpenAI
- 代码数据保护, 1. 加密. 2. Copilot 团队相关的 Github/OpenAI 的部分员工可看. 3. 访问时需基于角色的访问控制和多因素验证
- 避免代码片段被使用(保留或训练), 1. 设置 2. 联系 Copilot 团队
- 私有代码是否会被使用? 不会.
- 是否会输出个人信息(姓名生日等)? 少见, 还在改进.
- 详细隐私声明
常见问题
- Copilot 的训练数据, 来自 Github 的公开库.
- Copilot 写的代码完美吗? 不一定.
- 可以为新平台写代码吗? 暂时能力有限.
- 如何更好的使用 Copilot? 拆分代码为小函数, 用自然语言描述函数的功能, 以及输入输出, 使用有具体意义的变量名和函数名.
- Copilot 生成的代码会有 bug 吗? 当然无法避免.
- Copilot 生成的代码可以直接使用吗? 不一定, 有时候需要修改.
- Copilot 生成的代码可以用于商业项目吗? 可以.
- Copilot 生成的代码属于 Copilot 的知识产权吗? 不属于.
- Copilot 是从训练集里拷贝的代码吗? Copilot 不拷贝代码, 极低概率会出现超过 150 行代码能匹配到训练集, 以下两种情况会出现
- 在上下文信息非常少时
- 是通用问题的解决方案
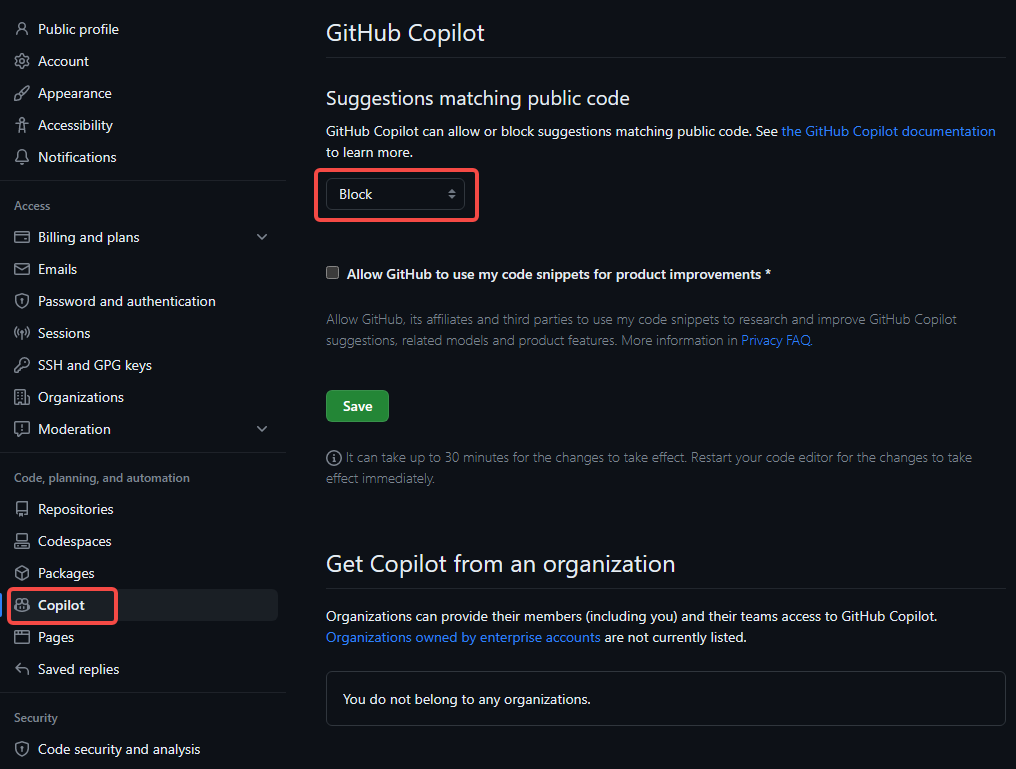
- 如何避免与公开代码重复, 设置filter
- 如何正确的使用 Copilot 生成的代码? 1. 自行测试/检视生成代码; 2. 不要在检视前自动编译或运行生成的代码.
- Copilot 是否在每种自然语言都有相同的表现? 最佳表现是英语.
- Copilot 是否会生成冒犯性内容? 已有过滤, 但是不排除可能出现.
Copilot使用入门
- 文档已过期
GitHub Copilot 是一款基于机器学习的代码补全工具,能帮助你更快速地编写代码并提升编码效率。
Copilot Labs 能力
| 能力 | 说明 | 备注 | example |
|---|---|---|---|
Explain |
生成代码片段的解释说明 | 有高级选项定制提示词, 更清晰说明自己的需求 | |
Show example code |
生成代码片段的示例代码 | 有高级选项定制 | |
Language Translation |
生成代码片段的翻译 | 此翻译是基于编程语言的翻译, 比如C++ -> Python | |
Readable |
提高一段代码的可读性 | 不是简单的格式化, 是真正的可读性提升 | |
Add Types |
类型推测 | 将自动类型的变量改为明确的类型 | |
Fix bug |
修复 bug | 修复一些常见的 bug | |
Debug |
使代码更容易调试 | 增加打印日志, 或增加临时变量以用于断点 | |
Clean |
清理代码 | 清理代码的无用部分, 注释/打印/废弃代码等 | |
List steps |
列出代码的步骤 | 有的代码的执行严格依赖顺序, 需要明确注释其执行顺序 | |
Make robust |
使代码更健壮 | 考虑边界/多线程/重入等 | |
Chunk |
将代码分块 | 一般希望函数有效行数<=50, 嵌套<=4, 扇出<=7, 圈复杂度<=20 | |
Document |
生成代码的文档 | 通过写注释生成代码, 还可以通过代码生成注释和文档 | |
Custom |
自定义操作 | 告诉 copilot 如何操作你的代码 | |
Copilot 是什么
官网 的介绍简单明了:Your AI pair programmer —— 你的结对程序员
结对编程:是一种敏捷软件开发方法,两个程序员在同一台计算机前协作:一人键入代码,另一人审视每行代码。角色时常互换,确保逻辑严谨、问题预防。
Copilot 通过以下方式参与编码工作, 实现扮演结对程序员这一角色.
理解
Copilot 是个大语言模型, 它不能理解我们的代码, 我们也不能理解 Copilot 的模型, 这里的理解是一名程序员与一群程序员之间的相互理解. 大家基于一些共识而一起写代码.
Copilot 搜集信息以理解上下文, 信息包括:
- 正在编辑的代码
- 关联文件
- IDE 已打开文件
- 库地址
- 文件路径
Copilot 不仅仅是通过一行注释去理解, 它搜集了足够多的上下文信息来理解下一步将要做什么.
建议
| 整段建议 | inline 建议 |
|---|---|
|
|
众所周知,最常见的获取建议方式是通过描述需求的注释而非直接编写代码,从而引导 GitHub Copilot 给出整段建议. 但这可能会造成注释冗余的问题, 注释不是越多越好, 注释可以帮助理解, 但它不是代码主体. 良好的代码没有注释也清晰明了, 依靠的是合适的命名, 合理的设计以及清晰的逻辑. 使用 inline 建议时, 只要给出合适的变量名/函数名/类名, Copilot 总能给出合适的建议.
除了合适的外部输入外, Copilot 也支持支持根据已有的代码片段给出建议, Copilot Labs->Show example code可以帮助生成指定函数的示例代码, 只需要选中代码, 点击Show example code.
Ctrl+Enter, 总是能给人非常多的启发, 我创建了三个文件, 一个 main.cpp 空文件, 一个 calculator.h 空文件, 在 calculator.cpp 中实现"加"和"减", Copilot 给出了如下建议内容:
- 添加"乘"和"除"的实现
- 在 main 中调用"加减乘除"的实现
- calculator 静态库的创建和使用方法
- main 函数的运行结果, 并且结果正确
- calculator.h 头文件的建议内容
- g++编译命令
- gtest 用例
- CMakeLists.txt 的内容, 并包含测试
- objdump -d main > main.s 查看汇编代码, 并显示了汇编代码
- ar 查看静态库的内容, 并显示了静态库的内容
默认配置下, 每次敲击Ctrl+Enter展示的内容差异很大, 无法回看上次生成的内容, 如果需要更稳定的生成内容, 可以设置temperature的值[0, 1]. 值越小, 生成的内容越稳定; 值越大, 生成的内容越难以捉摸.
以上建议内容远超了日常使用的一般建议内容, 可能是由于工程确实过于简单, 一旦把编译文件, 头文件写全, 建议就不会有这么多了, 但它仍然常常具有很好的启发作用.
使用 Copilot 建议的快捷键
| Action | Shortcut | Command name |
|---|---|---|
| 接受 inline 建议 | Tab |
editor.action.inlineSuggest.commit |
| 忽略建议 | Esc |
editor.action.inlineSuggest.hide |
| 显示下一条 inline 建议 | Alt+] |
editor.action.inlineSuggest.showNext |
| 显示上一条 inline 建议 | Alt+[ |
editor.action.inlineSuggest.showPrevious |
| 触发 inline 建议 | Alt+\ |
editor.action.inlineSuggest.trigger |
| 在单独面板显示更多建议 | Ctrl+Enter |
github.copilot.generate |
调试
一般两种调试方式, 打印和断点.
- Copilot 可以帮助自动生成打印代码, 根据上下文选用格式的打印或日志.
- Copilot 可以帮助修改已有代码结构, 提供方便的断点位置. 一些嵌套风格的代码难以打断点, Copilot 可以直接修改它们.
Copilot Labs 预置了以下功能:
- Debug, 生成调试代码, 例如打印, 断点, 以及其他调试代码.
检视
检视是相互的, 我们和 copilot 需要经常相互检视, 不要轻信快速生成的代码.
Copilot Labs 预置了以下功能:
- Fix bug, 直接修复它发现的 bug, 需要先保存好自己的代码, 仔细检视 Copilot 的修改.
- Make robust, 使代码更健壮, Copilot 会发现未处理的情况, 生成改进代码, 我们应该受其启发, 想的更缜密一些.
重构
Copilot Labs 预置了以下功能:
- Readable, 提高可读性, 真正的提高可读性, 而不是简单的格式化, 但是要务必小心的检视 Copilot 的修改.
- Clean, 使代码更简洁, 去除多余的代码.
- Chunk, 使代码更易于理解, 将代码分块, 将一个大函数分成多个小函数.
文档
Copilot Labs 预置了以下功能:
- Document, 生成文档, 例如函数注释, 以及其他文档.
使用 Custom 扩展 Copilot 边界
Custom不太起眼, 但它让 Copilot 具有无限可能. 我们可以将它理解为一种新的编程语言, 这种编程语言就是英语或者中文.
你可以通过 Custom 输入
-
移除注释代码
-
增加乘除的能力
-
改写为go
-
添加三角函数计算
-
添加微分计算, 中文这里不好用了, 使用support calculate differential, 在低温模式时, 没有靠谱答案, 高温模式时, 有几个离谱答案.
在日常工作中, 随时可以向 Copilot 提出自己的需求, 通过 Custom 能力, 可以让 Copilot 帮助完成许多想要的操作.
一些例子:
| prompts | 说明 |
|---|---|
generate the cmake file |
生成 cmake 文件 |
generate 10 test cases for tan() |
生成 10 个测试用例 |
format like google style |
格式化代码 |
考虑边界情况 |
考虑边界情况 |
确认释放内存 |
确认释放内存 |
Custom 用法充满想象力, 但有时也不那么靠谱, 建议使用前保存好代码, 然后好好检视它所作的修改.
获得更专业的建议
给 Copilot 的提示越清晰, 它给的建议越准确, 专业的提示可以获得更专业的建议. 许多不合适的代码既不影响代码编译, 也不影响业务运行, 但影响可读性, 可维护性, 扩展性, 复用, 这些特性也非常重要, 如果希望获得更专业的建议, 我们最好了解一些最佳实践的英文名称.
- 首先是使用可被理解的英文, 可以通过看开源项目学习英语.
- 命名约定, 命名是概念最基础的定义, 好的命名可以避免产生歧义, 避免阅读者陷入业务细节, 从而提高代码的可读性, 也是一种最佳实践.
- 通常只需要一个合理的变量名, Copilot 就能给出整段的靠谱建议.
- 设计模式列表, 设计模式是一种解决问题的模板, 针对不同问题合理取舍SOLID设计基本原则, 节省方案设计时间, 提高代码的质量.
- 只需要写出所需要的模式名称, Copilot 就能生成完整代码片段.
- 算法列表, 好的算法是用来解决一类问题的高度智慧结晶, 开发者需自行将具体问题抽象, 将数据抽象后输入到算法.
- 算法代码通常是通用的, 只需要写出算法名称, Copilot 就能生成算法代码片段, 并且 Copilot 总是能巧妙的将上下文的数据结构合理运用到算法中.
纯文本的建议
| en | zh |
|---|---|
| GitHub Copilot uses the OpenAI Codex to suggest code and entire functions in real-time, right from your editor. | GitHub Copilot 使用 OpenAI Codex 在编辑器中实时提供代码和整个函数的建议。 |
| Trained on billions of lines of code, GitHub Copilot turns natural language prompts into coding suggestions across dozens of languages. | 通过数十亿行代码的训练,GitHub Copilot 将自然语言提示转换为跨语言的编码建议。 |
| Don’t fly solo. Developers all over the world use GitHub Copilot to code faster, focus on business logic over boilerplate, and do what matters most: building great software. | 不要孤军奋战。世界各地的开发人员都在使用 GitHub Copilot 来更快地编码,专注于业务逻辑而不是样板代码,并且做最重要的事情:构建出色的软件。 |
| Focus on solving bigger problems. Spend less time creating boilerplate and repetitive code patterns, and more time on what matters: building great software. Write a comment describing the logic you want and GitHub Copilot will immediately suggest code to implement the solution. | 专注于解决更大的问题。花更少的时间创建样板和重复的代码模式,更多的时间在重要的事情上:构建出色的软件。编写描述您想要的逻辑的注释,GitHub Copilot 将立即提供代码以实现该解决方案。 |
| Get AI-based suggestions, just for you. GitHub Copilot shares recommendations based on the project’s context and style conventions. Quickly cycle through lines of code, complete function suggestions, and decide which to accept, reject, or edit. | 获得基于 AI 的建议,只为您。GitHub Copilot 根据项目的上下文和风格约定共享建议。快速循环代码行,完成函数建议,并决定接受,拒绝或编辑哪个。 |
| Code confidently in unfamiliar territory. Whether you’re working in a new language or framework, or just learning to code, GitHub Copilot can help you find your way. Tackle a bug, or learn how to use a new framework without spending most of your time spelunking through the docs or searching the web. | 在不熟悉的领域自信地编码。无论您是在新的语言或框架中工作,还是刚刚开始学习编码,GitHub Copilot 都可以帮助您找到自己的方式。解决 bug,或者在不花费大部分时间在文档或搜索引擎中寻找的情况下学习如何使用新框架。 |
这些翻译都由 Copilot 生成, 不能确定这些建议是基于模型生成, 还是基于翻译行为产生. 事实上你在表的en列中写的任何英语内容, 都可以被 Copilot 翻译(生成)到zh列中的内容.
设置项
客户端设置项
| 设置项 | 说明 | 备注 |
|---|---|---|
| temperature | 采样温度 | 0.0 - 1.0, 0.0 生成最常见的代码片段, 1.0 生成最不常见更随机的代码片段 |
| length | 生成代码建议的最大长度 | 默认 500 |
| inlineSuggestCount | 生成行内建议的数量 | 默认 3 |
| listCount | 生成建议的数量 | 默认 10 |
| top_p | 优先展示概率前 N 的建议 | 默认展示全部可能的建议 |
个人账户设置有两项设置, 一个是版权相关, 一个是隐私相关.
- 是否使用开源代码提供建议, 主要用于规避 Copilot 生成的代码片段中的版权问题, 避免开源协议限制.
- 是否允许使用个人的代码片段改进产品, 避免隐私泄露风险.
数据安全
Copilot 的信息收集
- 商用版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后立刻丢弃, 不保留任何代码片段
- 数据共享, GitHub, Microsoft, OpenAI
- 个人版
- 功能使用信息, 可能包含个人信息
- 搜集代码片段, 提供建议后, 根据个人 telemetry 设置, 保留或丢弃
- 代码片段包含, 正在编辑的代码, 关联文件, IDE 已打开文件, 库地址, 文件路径
- 数据共享, GitHub, Microsoft, OpenAI
- 代码数据保护, 1. 加密. 2. Copilot 团队相关的 Github/OpenAI 的部分员工可看. 3. 访问时需基于角色的访问控制和多因素验证
- 避免代码片段被使用(保留或训练), 1. 设置 2. 联系 Copilot 团队
- 私有代码是否会被使用? 不会.
- 是否会输出个人信息(姓名生日等)? 少见, 还在改进.
- 详细隐私声明
常见问题
- Copilot 的训练数据, 来自 Github 的公开库.
- Copilot 写的代码完美吗? 不一定.
- 可以为新平台写代码吗? 暂时能力有限.
- 如何更好的使用 Copilot? 拆分代码为小函数, 用自然语言描述函数的功能, 以及输入输出, 使用有具体意义的变量名和函数名.
- Copilot 生成的代码会有 bug 吗? 当然无法避免.
- Copilot 生成的代码可以直接使用吗? 不一定, 有时候需要修改.
- Copilot 生成的代码可以用于商业项目吗? 可以.
- Copilot 生成的代码属于 Copilot 的知识产权吗? 不属于.
- Copilot 是从训练集里拷贝的代码吗? Copilot 不拷贝代码, 极低概率会出现超过 150 行代码能匹配到训练集, 以下两种情况会出现
- 在上下文信息非常少时
- 是通用问题的解决方案
- 如何避免与公开代码重复, 设置filter
- 如何正确的使用 Copilot 生成的代码? 1. 自行测试/检视生成代码; 2. 不要在检视前自动编译或运行生成的代码.
- Copilot 是否在每种自然语言都有相同的表现? 最佳表现是英语.
- Copilot 是否会生成冒犯性内容? 已有过滤, 但是不排除可能出现.