Partage de l'expérience d'utilisation du mode Agent GitHub Copilot
Categories:
Cet article résume comment utiliser le mode Agent GitHub Copilot et partage des expériences pratiques.
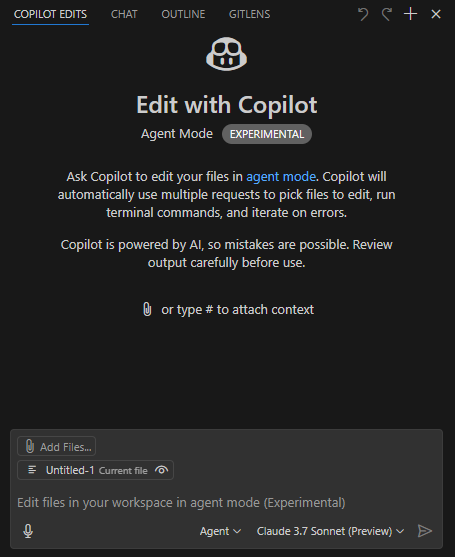
Configuration préalable
- Utiliser VSCode Insider ;
- Installer l’extension GitHub Copilot (version bêta) ;
- Choisir le modèle Claude 3.7 Sonnet (version bêta), excellent pour l’écriture de code, tandis que d’autres modèles offrent des avantages en termes de vitesse, de multimodalité (comme la reconnaissance d’images) et de capacité de raisonnement ;
- Choisir le mode de travail Agent.
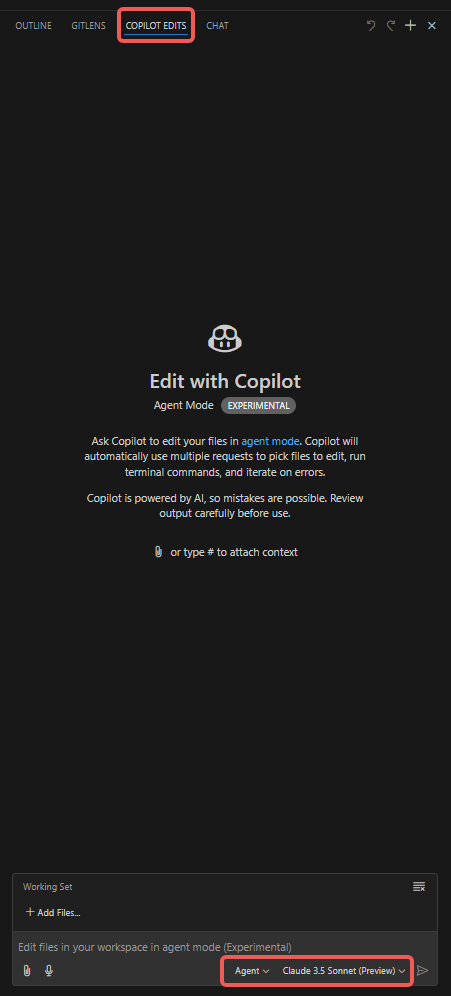
Étapes d’opération
- Ouvrir l’onglet « Copilot Edits » ;
- Ajouter des pièces jointes, comme « Codebase », « Get Errors », « Terminal Last Commands », etc. ;
- Ajouter les fichiers « Working Set », par défaut contenant le fichier actuellement ouvert, d’autres fichiers peuvent être sélectionnés manuellement (comme « Open Editors ») ;
- Ajouter les « Instructions », saisir les mots-clés que Copilot Agent doit particulièrement noter ;
- Cliquer sur le bouton « Send » pour commencer la conversation et observer le comportement de l’Agent.
Autres remarques
- L’IDE peut générer des messages d’erreur ou d’avertissement via les fonctionnalités de lint fournies par les plugins de langue, l’Agent peut automatiquement corriger le code selon ces messages.
- Au fur et à mesure que la conversation progresse, les modifications de code générées par l’Agent peuvent s’écarter des attentes. Il est recommandé de se concentrer sur un sujet clair à chaque session, d’éviter les conversations trop longues ; terminer la session actuelle une fois l’objectif à court terme atteint, puis lancer une nouvelle tâche.
- L’option « Add Files » sous « Working Set » fournit une option « Related Files » pour recommander des fichiers connexes.
- Faire attention à contrôler le nombre de lignes d’un seul fichier de code pour éviter une consommation excessive de tokens.
- Il est recommandé de générer d’abord le code de base, puis d’écrire des cas de test, afin que l’Agent puisse déboguer et s’auto-valider selon les résultats des tests.
- Pour limiter la portée des modifications, ajouter la configuration suivante dans settings.json afin de ne modifier que les fichiers du répertoire spécifié, à titre indicatif uniquement :
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "Ne modifier que les fichiers du répertoire ./script/, ne pas modifier les fichiers d'autres répertoires."
},
{
"text": "Si le nombre de lignes du fichier de code cible dépasse 1000 lignes, il est recommandé de placer les nouvelles fonctions dans un nouveau fichier et de les appeler par référence ; si les modifications entraînent un fichier trop long, cette règle peut temporairement ne pas être strictement respectée."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "Générer des cas de test dans les fichiers de tests unitaires existants."
},
{
"text": "Il est impératif d'exécuter les cas de test pour valider après toute modification de code."
}
],
Problèmes courants
Les exigences saisies ne produisent pas le code métier souhaité
Il est nécessaire de décomposer une grande tâche en tâches plus petites et de ne traiter qu’une petite tâche à chaque session. Cela est dû au fait que trop de contexte dans un grand modèle peut disperser l’attention.
Le contexte fourni à une conversation unique doit être soigneusement évalué ; trop ou trop peu peut entraîner une mauvaise compréhension des besoins.
Le modèle DeepSeek résout le problème de la dispersion de l’attention, mais nécessite l’utilisation de l’API Deepseek dans cursor. L’efficacité de cette solution reste à confirmer.
Problème de lenteur de réponse
Il est nécessaire de comprendre le mécanisme de consommation de tokens ; l’entrée de tokens est bon marché et prend moins de temps, tandis que la sortie de tokens est beaucoup plus coûteuse et nettement plus lente.
Si un fichier de code est très grand, mais que seules trois lignes de code doivent être modifiées, en raison du grand contexte et d’une sortie importante, la consommation de tokens sera rapide et la réponse lente.
Par conséquent, il est indispensable de contrôler la taille des fichiers, d’éviter d’écrire de gros fichiers et de grandes fonctions. Il faut scinder rapidement les gros fichiers et les grandes fonctions, et les appeler par référence.
Problème de compréhension métier
Le problème de compréhension peut dépendre en partie des commentaires dans le code et des fichiers de test. Compléter suffisamment les commentaires et les cas de test dans le code aide Copilot Agent à mieux comprendre le métier.
Le code métier généré par l’Agent lui-même contient suffisamment de commentaires ; en examinant ces commentaires, on peut rapidement déterminer si l’Agent comprend correctement les besoins.
Génération d’une grande quantité de code nécessitant un long débogage
On peut envisager de générer d’abord les cas de test après avoir produit le code de base pour une certaine fonctionnalité, puis d’ajuster la logique métier. Ainsi, l’Agent peut effectuer son propre débogage et s’auto-valider.
L’Agent demandera s’il peut exécuter les commandes de test. Après l’exécution, il lira la sortie du terminal pour déterminer si le code est correct. S’il ne l’est pas, il modifiera le code selon les informations d’erreur. Ce processus se répète jusqu’à ce que les tests réussissent.
Autrement dit, il faut comprendre davantage le métier soi-même ; les moments où il est nécessaire d’écrire manuellement ne sont pas nombreux. Seulement lorsque ni le code des cas de test ni le code métier ne sont corrects, l’Agent ne peut pas écrire les bons cas de test selon le métier, ni écrire le bon code métier selon les cas de test. C’est dans ces cas que le débogage peut être long.
Conclusion
Comprendre le mécanisme de consommation de tokens du grand modèle, le contexte d’entrée est bon marché et prend peu de temps, tandis que le code de sortie est plus cher et se produit plus lentement. Les parties du fichier non modifiées pourraient aussi être comptées comme sortie, preuve en est que beaucoup de code inutile est également affiché lentement.
Par conséquent, il faut contrôler autant que possible la taille d’un seul fichier. On peut ressentir la différence de vitesse de réponse de l’Agent lorsqu’il traite de gros et de petits fichiers, et cette différence est très marquée.