Github Copilot Agent 모드 사용 경험 공유
Categories:
본문은 GitHub Copilot Agent 모드 사용 방법을 정리하고 실제 운영 경험을 공유합니다.
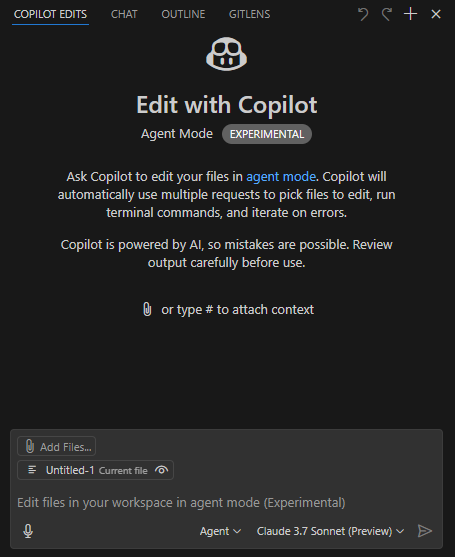
사전 설정
- VSCode Insider 사용;
- GitHub Copilot(미리보기) 플러그인 설치;
- Claude 3.7 Sonnet(미리보기) 모델 선택. 이 모델은 코드 작성에서 뛰어난 성능을 보이며, 다른 모델은 속도, 멀티모달(이미지 인식 등), 추론 능력에서 강점이 있음;
- 작업 모드는 Agent로 선택.
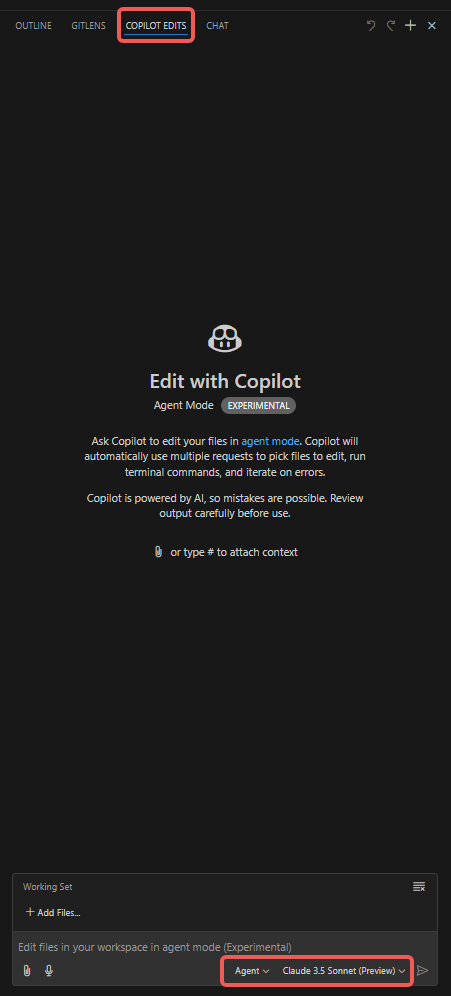
작업 절차
- “Copilot Edits” 탭 열기;
- 첨부파일 추가, 예: “Codebase”, “Get Errors”, “Terminal Last Commands” 등;
- “Working Set” 파일 추가, 기본적으로 현재 열린 파일을 포함하며, 수동으로 다른 파일(예: “Open Editors”) 선택 가능;
- “Instructions” 추가, Copilot Agent가 특히 주의해야 할 프롬프트 입력;
- “Send” 버튼 클릭, 대화 시작, Agent 행동 관찰.
기타 설명
- VSCode는 언어 플러그인이 제공하는 lint 기능을 통해 Error 또는 Warning 알림을 생성할 수 있으며, Agent는 이러한 알림에 따라 자동으로 코드를 수정할 수 있습니다.
- 대화가 깊어질수록 Agent가 생성한 코드 수정이 예상에서 벗어날 수 있습니다. 각 세션은 명확한 주제에 집중하고 대화를 길게 하지 않는 것이 좋으며, 단기 목표에 도달하면 현재 세션을 종료하고 새로운 작업을 시작하는 것이 권장됩니다.
- “Working Set"의 “Add Files"에서 “Related Files” 옵션을 제공하여 관련 파일을 추천합니다.
- 단일 코드 파일의 행 수를 제어하여 token 소비가 빠르게 이루어지는 것을 방지하는 것이 좋습니다.
- 기본 코드를 먼저 생성한 후 테스트 케이스를 작성하는 것이 좋으며, 이를 통해 Agent가 테스트 결과에 따라 디버깅하고 자기 검증할 수 있습니다.
- 수정 범위를 제한하기 위해 settings.json에 다음 구성을 추가하는 것이 좋으며, 참고용입니다:
"github.copilot.chat.codeGeneration.instructions": [
{
"text": " ./script/ 디렉토리의 파일만 수정하고 다른 디렉토리의 파일은 수정하지 마십시오."
},
{
"text": "목표 코드 파일의 행 수가 1000행을 초과하면 새 파일에 추가 함수를 배치하고 참조를 통해 호출하는 것이 좋습니다. 생성된 수정으로 인해 파일이 너무 길어지는 경우 이 규칙을 엄격히 준수하지 않아도 됩니다."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "기존 단위 테스트 파일에서 테스트 케이스를 생성합니다."
},
{
"text": "코드 수정 후 반드시 테스트 케이스를 실행하여 검증합니다."
}
],
일반적인 문제
입력 요구사항으로 원하는 비즈니스 코드를 얻지 못함
대규모 작업을 더 작은 작업으로 분해하여 각 세션이 작은 작업만 처리하도록 해야 합니다. 이는 대형 모델의 컨텍스트가 많을수록 주의력이 분산되기 때문입니다.
단일 대화에 제공하는 컨텍스트는 스스로 고민해야 하며, 너무 많거나 적으면 요구사항을 이해하지 못하게 됩니다.
DeepSeek 모델은 주의력 분산 문제를 해결했지만, cursor에서 Deepseek API를 사용해야 합니다. 그 효과가 어떠한지는 불확실합니다.
응답 지연 문제
token 소비 메커니즘을 이해해야 합니다. token 입력은 저렴하고 시간이 짧으며, token 출력은 훨씬 비싸고 명백히 느립니다.
코드 파일이 매우 크고 실제로 수정이 필요한 코드 행이 세 줄뿐이라도 컨텍스트가 많고 출력도 많으면 token 소비가 빠르게 이루어지고 응답이 느려집니다.
따라서 파일 크기를 제어해야 하며, 너무 큰 파일과 큰 함수를 작성하지 않는 것이 좋습니다. 대파일과 대함수를 적시에 분리하고 참조를 통해 호출하는 것이 좋습니다.
비즈니스 이해 문제
문제 이해는 코드의 주석과 테스트 파일에 어느 정도 의존할 수 있습니다. 코드에 충분한 주석과 테스트 케이스를 보충하면 Copilot Agent가 비즈니스를 더 잘 이해하는 데 도움이 됩니다.
Agent가 스스로 생성한 비즈니스 코드에는 충분한 주석이 포함되어 있으며, 이러한 주석을 검토하면 Agent가 요구사항을 올바르게 이해했는지 빠르게 판단할 수 있습니다.
생성된大量 코드로 인한 장시간 디버깅
특정 기능의 기본 코드를 생성한 후 먼저 테스트 케이스를 생성하고, 그 다음에 비즈니스 로직을 조정하는 것을 고려할 수 있습니다. 이를 통해 Agent가 스스로 디버깅하고 자기 검증할 수 있습니다.
Agent는 테스트 명령을 실행할 수 있는지 물어볼 것이며, 실행이 완료되면 터미널 출력을 직접 읽어 코드가 올바른지 판단합니다. 올바르지 않으면 오류 메시지에 따라 수정합니다. 이를 반복하여 테스트가 통과할 때까지 진행합니다.
즉, 더 많은 비즈니스를 이해해야 하며, 수동으로 작성해야 할 때는 그리 많지 않습니다. 테스트 케이스 코드와 비즈니스 코드가 모두 올바르지 않으면 Agent는 비즈니스에 따라 올바른 케이스를 작성할 수 없고 케이스에 따라 올바른 비즈니스 코드를 작성할 수도 없습니다. 이러한 경우에만 장시간 디버깅이 발생합니다.
요약
대형 모델의 token 소비 메커니즘을 이해해야 합니다. 입력 컨텍스트는 저렴하고 수정되지 않은 코드 부분도 출력으로 계산될 수 있습니다. 증거는 수정이 필요하지 않은 많은 코드도 천천히 출력되는 것입니다.
따라서 단일 파일 크기를 최대한 제어해야 하며, Agent가 대형 파일과 소형 파일을 처리할 때의 응답 속도 차이를 직접 경험해 볼 수 있습니다. 이 차이는 매우 명확합니다.