مشاركة تجربة استخدام نمط وكيل GitHub Copilot
Categories:
تلخص هذه المقالة كيفية استخدام نمط وكيل GitHub Copilot، ومشاركتها لخبرات التشغيل الفعلية.
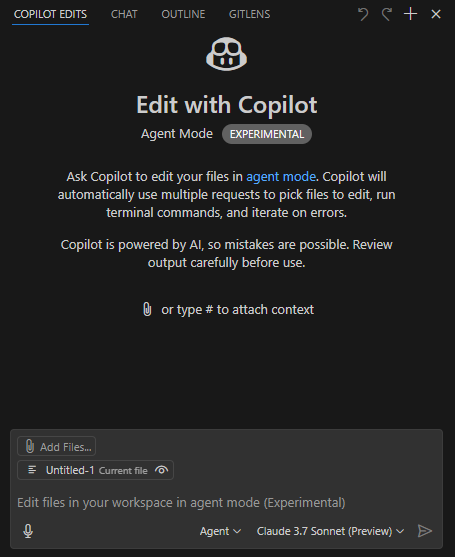
الإعداد المسبق
- استخدام VSCode Insider؛
- تثبيت ملحق GitHub Copilot (نسخة تجريبية)؛
- اختيار نموذج Claude 3.7 Sonnet (نسخة تجريبية)، حيث يُظهر هذا النموذج أداءً ممتازًا في كتابة الشفرة، مع امتلاك نماذج أخرى مزايا في السرعة، والقدرة على التعامل مع الوسائط المتعددة (مثل التعرف على الصور) والقدرة على الاستدلال؛
- اختيار نمط العمل Agent.
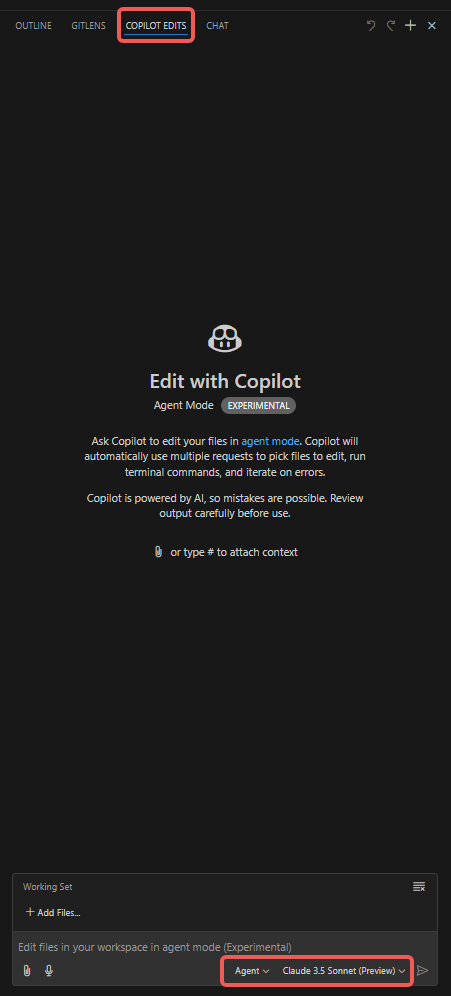
خطوات التشغيل
- فتح علامة تبويب “Copilot Edits”؛
- إضافة المرفقات، مثل “Codebase” و “Get Errors” و “Terminal Last Commands”؛
- إضافة ملفات “Working Set”، حيث تحتوي بشكل افتراضي على الملفات المفتوحة حاليًا، ويمكن أيضًا اختيار ملفات أخرى يدويًا (مثل “Open Editors”)؛
- إضافة “Instructions”، وإدخال التعليمات التي يجب على وكيل Copilot الانتباه إليها بشكل خاص؛
- النقر على زر “Send” لبدء المحادثة ومراقبة أداء الوكيل.
ملاحظات أخرى
- يمكن لـ VSCode إنتاج إشعارات خطأ أو تحذير من خلال ميزة lint التي يوفرها ملحق اللغة، ويمكن للوكيل تصحيح الشفرة تلقائيًا وفقًا لهذه الإشعارات.
- مع تعمق المحادثة، قد تبتعد تعديلات الشفرة التي يولدها الوكيل عن التوقعات. يُقترح أن تركز كل جلسة على موضوع واضح، وتجنب المحادثات الطويلة جدًا؛ بعد تحقيق الهدف قصير المدى، أنهِ الجلسة الحالية وابدأ مهمة جديدة.
- توفر خيار “Add Files” في “Working Set” خيار “Related Files” لاقتراح ملفات ذات صلة.
- انتبه إلى التحكم في عدد أسطر ملف الشفرة الواحد، لتجنب استهلاك الـ token بسرعة كبيرة.
- يُقترح إنشاء الشفرة الأساسية أولاً، ثم كتابة حالات الاختبار، مما يساعد الوكيل على تصحيح الشفرة والتحقق منها ذاتيًا بناءً على نتائج الاختبار.
- لتحديد نطاق التعديل، يمكن إضافة التكوين التالي في settings.json للتعديل فقط على الملفات في الدليل المحدد،仅供参考:
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "يُسمح بالتعديل فقط على الملفات الموجودة في الدليل ./script/ ولا يُسمح بالتعديل على الملفات في الدلائل الأخرى."
},
{
"text": "إذا تجاوز عدد أسطر ملف الشفرة المستهدف 1000 سطر، يُقترح وضع الدالة الجديدة في ملف منفصل والاعتماد على الاستدعاء من خلال الإشارة؛ وإذا تسبب التعديل الناتج في تجاوز طول الملف للحد المسموح، يمكن تجاهل هذه القاعدة مؤقتًا."
}
],
"github.copilot.chat.testGeneration.instructions": [
{
"text": "توليد حالات الاختبار في ملفات الاختبار الوحدوية الحالية."
},
{
"text": "يجب تشغيل حالات الاختبار للتحقق بعد تعديل الشفرة."
}
],
الأسئلة الشائعة
لا تحصل على شفرة أعمال مطلوبة عند إدخال المتطلبات
يجب تقسيم المهام الكبيرة إلى مهام أصغر، مع معالجة مهمة صغيرة واحدة فقط في كل جلسة محادثة. هذا ناتج عن تشتيت انتباه نموذج اللغة الكبير عندما يكون السياق كثيرًا.
يجب أن ت揣ّن السياق المعروض في كل محادثة، حيث أن كثرة السياق أو قلته قد يؤدي إلى عدم فهم المتطلبات.
لقد حل نموذج DeepSeek مشكلة تشتيت الانتباه، ولكن يجب استخدام Deepseek API في cursor. لا نعرف مدى فعالية ذلك.
مشكلة البطء في الاستجابة
يجب فهم آلية استهلاك الـ token، حيث يكون إدخال الـ token أرخص وأسرع، بينما يكون إخراج الـ token أغلى بكثير وأبطأ بشكل ملحوظ.
افترض أن ملف شفرة كبير جدًا، ولكن في الواقع تحتاج فقط إلى تعديل ثلاث أسطر من الشفرة، ولكن بسبب السياق الكبير، يكون الإخراج أيضًا كبيرًا، مما يؤدي إلى استهلاك سريع للـ token وبطء في الاستجابة.
لذلك، يجب التفكير في التحكم في حجم الملف، وعدم كتابة ملفات كبيرة أو وظائف كبيرة. قم بتقسيم الملفات والوظائف الكبيرة في الوقت المناسب، واستخدم الاستدعاء من خلال الإشارة.
مشكلة فهم الأعمال
قد يعتمد فهم المشكلة إلى حد ما على التعليقات في الشفرة، وملفات الاختبار، وتكملة تعليقات كافية في الشفرة، وحالات الاختبار، مما يساعد Copilot Agent على فهم أفضل لأعمالك.
الشفرة التجارية التي يولدها Agent نفسه تحتوي على تعليقات كافية، وفحص هذه التعليقات يمكن أن يحدد بسرعة ما إذا كان Agent قد فهم المتطلبات بشكل صحيح.
يتطلب إنشاء كمية كبيرة من الشفرة وقتًا أطول للتصحيح
يمكن التفكير في إنشاء حالات الاختبار بعد إنشاء الشفرة الأساسية لسمة معينة، ثم تعديل المنطق التجاري، بحيث يمكن للوكيل إجراء التصحيح والتحقق الذاتي.
سيسألك Agent عما إذا كان يُسمح له بتشغيل أمر الاختبار، وبعد الانتهاء من التشغيل، سيقرأ الإخراج من الطرفية بنفسه لتحديد ما إذا كانت الشفرة صحيحة. إذا لم تكن كذلك، فسوف يقوم بالتعديل وفقًا لمعلومات الخطأ. يتكرر هذا الدوران حتى يمر الاختبار.
بمعنى آخر، تحتاج إلى فهم أكبر للأعمال، ولا يكون لديك الكثير من الشفرة التي تحتاج إلى كتابتها يدويًا. في الحالات التي تكون فيها شفرة اختبار الوحدة وشفرة الأعمال غير صحيحة، لا يمكن للوكيل كتابة حالة اختبار صحيحة وفقًا للأعمال، ولا يمكنه كتابة شفرة أعمال صحيحة وفقًا لحالة الاختبار. فقط في هذه الحالة ستظهر حالة التصحيح الطويل.
ملخص
فهم آلية استهلاك الـ token لنموذج اللغة الكبير، حيث يكون السياق المدخل رخيصًا وسريعًا نسبيًا، بينما يكون الكود المخرج مكلفًا نسبيًا، وربما يُحسب جزء الشفرة غير المعدل في الملف كمخرج أيضًا. الدليل على ذلك هو أن العديد من الشفرة التي لا تحتاج إلى تعديل تُخرج ببطء شديد.
لذلك، يجب التحكم في حجم ملف الشفرة الواحدة قدر الإمكان، ويمكن الشعور بالفرق في سرعة استجابة Agent عند التعامل مع الملفات الكبيرة والصغيرة أثناء الاستخدام، وهذا الفرق واضح جدًا.